Figure 4
From: RSEM: accurate transcript quantification from RNA-Seq data with or without a reference genome

The directed graphical model used by RSEM. The model consists of N sets of random variables, one per sequenced RNA-Seq fragment. For fragment n, its parent transcript, length, start position, and orientation are represented by the latent variables G
n
, F
n
, S
n
and O
n
respectively. For PE data, the observed variables (shaded circles), are the read lengths (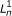 and
and 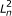 ), quality scores (
), quality scores (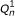 and
and  ), and sequences (
), and sequences (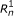 and
and 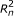 ). For SE data, , , and are unobserved. The primary parameters of the model are given by the vector θ, which represents the prior probabilities of a fragment being derived from each transcript.
). For SE data, , , and are unobserved. The primary parameters of the model are given by the vector θ, which represents the prior probabilities of a fragment being derived from each transcript.