- Research article
- Open access
- Published:
Linear MALDI-ToF simultaneous spectrum deconvolution and baseline removal
BMC Bioinformatics volume 19, Article number: 123 (2018)
Abstract
Background
Thanks to a reasonable cost and simple sample preparation procedure, linear MALDI-ToF spectrometry is a growing technology for clinical microbiology. With appropriate spectrum databases, this technology can be used for early identification of pathogens in body fluids. However, due to the low resolution of linear MALDI-ToF instruments, robust and accurate peak picking remains a challenging task. In this context we propose a new peak extraction algorithm from raw spectrum. With this method the spectrum baseline and spectrum peaks are processed jointly. The approach relies on an additive model constituted by a smooth baseline part plus a sparse peak list convolved with a known peak shape. The model is then fitted under a Gaussian noise model. The proposed method is well suited to process low resolution spectra with important baseline and unresolved peaks.
Results
We developed a new peak deconvolution procedure. The paper describes the method derivation and discusses some of its interpretations. The algorithm is then described in a pseudo-code form where the required optimization procedure is detailed. For synthetic data the method is compared to a more conventional approach. The new method reduces artifacts caused by the usual two-steps procedure, baseline removal then peak extraction. Finally some results on real linear MALDI-ToF spectra are provided.
Conclusions
We introduced a new method for peak picking, where peak deconvolution and baseline computation are performed jointly. On simulated data we showed that this global approach performs better than a classical one where baseline and peaks are processed sequentially. A dedicated experiment has been conducted on real spectra. In this study a collection of spectra of spiked proteins were acquired and then analyzed. Better performances of the proposed method, in term of accuracy and reproductibility, have been observed and validated by an extended statistical analysis.
Background
Linear matrix-assisted laser desorption/ionization time-of-flight mass spectrometry (MALDI-ToF MS) has now revolutionized identification of bacteria, yeasts and molds in clinical microbiology [1]. The technology is simple, accurate, fast, and for large laboratories less expensive than conventional methods. Despite a lower resolution than other analyzers used in modern proteomics, linear ToF are preferred in microbiology because of a better sensitivity in the 2-20 kDa mass range, where proteins contain phylogenic information. Moreover, the lower cost of linear instruments favored a wider adoption by health institutions. In essence, identifications are performed in minutes by simply acquiring an experimental spectrum of the whole microorganism cells and comparing the resulting peak list with a database [2, 3]. In this context we propose a new method for peak extraction especially adapted to linear MALDI-ToF spectra. The usual approach for MALDI mass spectra processing generally consists of chaining several procedures. Most of the times we have a smoothing step, a baseline correction step and only then the final the peak extraction [4]. The main idea of our new method is to jointly perform these steps with the aim of reducing the potential unrecoverable artifacts introduced by a sequential processing. In the next sections we briefly present the three main steps of the usual approaches. We then describe our method and its detailed derivation.
Smoothing
A popular [5] smoothing technique in the spectrometry community is the use of Savitzky-Golay linear filters [6, 7]. These moving average filters perform a least squares fit of a small set of consecutive data points to a polynomial. The value of this fitted polynomial at the window central point is the filter output. One can also compute a smoothed derivative by using the derivative of the fitted polynomial to compute the central point value. This smoothed derivative can also be used by peak picking algorithms [4]. This method is versatile and efficient. However, its main drawbacks are that we have to manually choose the polynomial degree and the window length. Some studies to automatically choose the former [8] or later [9] exist but to the best of our knowledge they are not used as often as the original approach.
A more recent approach to smooth spectra is the use the wavelet transform. The Undecimated Wavelet Transform (UDWT) [10, 11] is generally preferred to the Discrete Wavelet Transform (DWT) as it produces less artifacts after coefficient thresholding. The UDWT is equivalent to an averaged DWT computed for all integer shifts of the signal and is thus a redundant and shift invariant transform. In applications it has been reported to yield better qualitative denoising [12].
Baseline correction
Baseline correction is a difficult problem that potentially also introduces artifacts [13]. There are at least two kinds of approaches for baseline correction. One category of methods is close to mathematical morphology. In these methods a lower envelope of the spectrum [14, 15] is computed. Methods of this category generally need a smoothed signal (see “Smoothing” section). The other category contains methods using an asymmetric loss function to fit spectrum baseline without being biased by peaks [16, 17]. Finally some other methods mix the two previous approaches [18].
Peak picking
After baseline removal the next step is generally a peak picking procedure. Several approaches are possible. Perhaps the most intuitive approach is to compute a regularized second order derivative (using Savitzky-Golay for instance) of the spectrum and to extract local minima [4]. The use of second order derivative minima instead of the zero-crossing of the first order derivative allows, to some extend, to detect overlapping peaks [19].
A second kind of approach, especially useful in case of overlapping peaks, is peak deconvolution. Overlapping of complex peak patterns can be deconvolved if one uses specially tuned point spread function and judicious regularizations (positivity constraint and sparsity-inducing norms, like the l1 norm) [20–23]. Further generalizations can be obtained in case of blind-deconvolution [24]. However these kinds of approaches are much more computationally intensive and are not widely used in mass spectrometry.
Finally we can mention the Continuous Wavelet Transform (CWT) [25, 26] which can be efficiently computed using the Fast Fourier Transform. The idea is to follow wavelet modulus maximum. Theses ridges characterize the regularity of the signal [27] and can be used to detect peaks.
Contributions
Computing the baseline correction and finding peaks are two strongly linked problems, it is thus natural to perform these two operations jointly. In this work we propose such an approach.
In the first part of the paper we describe a direct model with an additive noise where the spectrum is modelized by a smooth baseline plus a sparse peak list convolved by a given peak shape function. We describe how we chose our priors to enforce baseline smoothness and sparsity of the peak list. We then assume a Gaussian distribution for the noise. This allows us to use Euclidean distance to quantify the error between our model and the measured spectrum.
Next we show how the unknown baseline can be eliminated from the model. This manipulation leads to a modified problem very close to the classical deconvolution one. We underline this similarity and rigorously describe the two limiting cases, zero or infinite penalization for the baseline smoothness. As a by product we can interpret that our new deconvolution method is equivalent in some way to deconvolve a regularized second order derivative of the initial spectrum.
We then carefully examine the behavior of the computed baseline at the spectrum boundaries. We observed that when the smoothness penalty is too strong, the computed baseline can become overly flat. To avoid this effect a correction allowing to define baseline values at boundaries is proposed. With this modification the behavior of the baseline at the boundaries is no more affected by strong baseline smoothness penalty.
An effective optimization method to compute the solution of the deconvolution problem is exposed. This optimization algorithm is used twice in our two-passes deconvolution procedure. In the first pass a sparsity prior is used and a first optimization problem is solved to find peak centers. In the second pass the sparsity prior is replaced by the previously found peak positions. This second optimization problem is solved to compute peak height values.
Finally the new method is compared to one instance of the smoothing/baseline correction/deconvolution classical approach. The advantage of the joint baseline computation and peak deconvolution is demonstrated on synthetic data. An example on “real” data is shown and a reference to a more detailed comparison between our method and classical ones is given.
Method
Problem definition
The proposed developments are founded on a natural model for the observed spectrum y as a spiky signal x p convolved with a peak shape p superimposed onto a smooth baseline x b
where e includes measurement and model errors. It is a common linear model with additive uncertainties. These quantities are represented by vectors of size n, where n is the number of m/z channels of the original spectrum y.
The problem at stake is to recover both the signal of interest x p and the baseline x b . It is a difficult task at least for three reasons.
-
It is underdetermined since the number of unknowns is twice the number of data.
-
The convolution reduces the resolution due to peak enlargement and possible overlap.
-
Measurement noise and possible model inadequacy induce additional uncertainties.
As a consequence, information must be accounted for regarding the expected signals x p and x b . In the following developments, x b is expected to be smooth while x p is expected to be spiky and positive. This knowledge will be included in the next sections.
x b smoothness
A simple way to account for smoothness of x b is to penalize its fluctuations through
where D is a finite differences matrix of size (n−1)×n (given in Appendix “Smoothness and convolution matrix”) and μ>0.
x p sparsity and positivity
In order to favor sparsity for x p (spiky property) an elastic-net penalty is introduced
The degree of sparsity is controlled by λ1. The coefficient λ2 is generally set to zero or to a very small value. The reason why we have introduced this extra regularization is that a small positive value can sometimes improve convergence speed of the algorithm. In practice this only happens for spectra of several thousand of m/z channels and always has a limited impact on the obtained solution.
In addition, the solution also requires positivity of x p , i.e. positivity for each component x p [ k]. The l1 norm then simplifies
where \(\mathbb {1}_{n}\) is the n dimensional column vector with each entry to 1. This substitution turns the convex, but nonsmooth, penalty \(\mathcal {P}_{p}(\mathbf {x}_{p})\) into a smooth quadratic one. This idea has already been used in [23, 28].
Data-fidelity term
A common and natural way to quantify data - model discrepancy founded on Eq. 1 relies on a squared Euclidean norm:
where the n×n band matrix L represents the convolution with the peak shape p.
Complete objective
Using Eqs. 2, 3 and 4, we get a first expression of the complete objective:
that is to say:
The minimization of this objective function
gives the desired solution \(\left (\widehat {\mathbf {x}}_{p},\widehat {\mathbf {x}}_{b}\right)\).
Elimination of x b
To find the solution of problem Eq. 7 we begin by solving it for the x b vector. This is an unconstrained quadratic problem and an analytical solution can be found. We shall first write down the gradient of \(\mathcal {J}\) with respect to x b :
Solving \(\nabla _{\mathbf {x}_{b}} \mathcal {J} =0\) yields the minimizer:
where \(\mathbf {B}_{\mu }=\mathbf {I}_{b}+\mu \mathbf {D}^{t}\mathbf {D}\). This operation is always possible since B μ is invertible (sum of the identity matrix and a semi-positive matrix).
It is then possible to substitute x b for \(\widehat {\mathbf {x}}_{b}\) in objective Eq. 5 to obtain a reduced objective. After some algebra (proof is given in Appendix “Derivation of reduced objective”), we have
where C is a constant, and \(\widetilde {\mathcal {J}}(\mathbf {x}_{p})\) is defined by:
The matrix A μ is defined by:
and its interpretation is discussed in detail in “Analysis of the A μ matrix” section).
This quadratic form \(\widetilde {\mathcal {J}}(\mathbf {x}_{p})\) is our objective function and the solution \(\widehat {\mathbf {x}}_{p}\) is its minimizer subject to positivity:
Once this constrained quadratic problem is solved, we can retrieve \(\widehat {\mathbf {x}}_{b}\) using Eq. 9:
then the initial problem Eq. 7 is solved.
The gradient of \(\widetilde {\mathcal {J}}(\mathbf {x}_{p})\) is easily deduced form Eq. 10 and reads:
Interpretation of the reduced criterion
We can make a pause here to interpret Eq. 12. If there was no baseline a natural way to deconvolve the spectrum would be to solve:
If we use the positivity constraint and expand this objective function we get the following equivalent problem:
Now if we look Eq. 10 and set λ2=0 we get:
The two equations are very similar apart from the fact that the operator A μ is applied to the reconstructed peaks Lx p and to the raw spectrum y. It could be interpreted as the precision (inverse of the covariance) matrix in a correlated noise framework. Instead of this classical approach and to better understand its role in our deconvolution context we study the evolution of A μ in the two limiting cases \(\mu \rightarrow 0\) and \(\mu \rightarrow \infty \).
Analysis of the A μ matrix
Figure 1 shows the column \(j=\lfloor {\frac {n}{2}}\rfloor \) of A μ for two different values of μ.

A μ operator. \(\mathbf {A}_{\mu }\left (:,\lfloor {\frac {n}{2}}\rfloor \right)\) column plot for μ=1 and μ=100. A μ operator acts like a regularized second order derivation. The regularization strength increases as μ increases (μ is the background smoothness parameter)
For small μ, the A μ operator acts like a regularized second order derivation. For a sufficiently small μ (such that the spectral radius satisfies ρ(μDtD)<1) a Taylor expansion gives:
Hence compared to Eq. 14, one can interpret Eq. 15 as an usual deconvolution applied on the second order derivative A μ y of the initial spectrum y. The used point spread function is also the second order derivative A μ L of the initial peak shape p introduced in Eq. 1. The overall effect of the A μ operator is to cancel the slow varying component of the signal. In another terms, the baseline is removed thanks to a derivation.
The regularization strength increases as the baseline parameter μ increases. At the limit \(\mu \rightarrow \infty \) (proof given in Appendix “Expression of \( \underset{\mu \to \infty }{\lim }{\mathbf{A}}_{\mu } \)”) we get:
When applied to any vector y we get
Thus the action of A μ centers the signal y by subtracting the constant \(\bar {\mathbf {y}}\mathbb {1}_{n}\) vector, where the scalar \(\bar {\mathbf {y}}\) is the mean value of the y vector’s components. The same centering holds for the peak shape function p. It follows that in this limiting case the solved problem is the usual deconvolution procedure applied on the centered spectrum. The computed baseline is simply a constant equal to the spectrum mean.
Debiasing
The l1 penalty acts as a soft threshold to select peaks ([29], Section 10). This leads to a bias in peak intensity estimation. These intensities are artificially reduced when the l1 penalty increases. We use the ideas introduced in [28] to get corrected peak intensities. This yields a resolution procedure involving two stages. The first stage selects the peaks, the second one corrects their intensities.
First stage: peak support selection
Given μ, λ1 and λ2, we solve the minimization problem Eq. 12. The obtained solution \(\widehat {\mathbf {x}}_{p}\) is a sparse vector containing peak intensities. The intensities are biased if the λ hyper-parameters are not null. However we can use \(\widehat {\mathbf {x}}_{p}\) to define the peak support Ω. In the present work the peak support is simply defined by keeping the local maxima of \(\widehat {\mathbf {x}}_{p}\).
The peak intensities are going to be corrected in the second stage, but their final positions are defined by the condition Eq. 16. More complex procedures can be used to find the peak support. One such example is the procedure presented in [22], Post-processing and thresholding. These more refined methods can be introduced in a straightforward way in our approach by using them instead of the basic condition Eq. 16.
Second stage: peak intensity correction
In the second step, as we have peak support Ω, we do not need the l1 regularization anymore. Hence we simply ignore it and solve the simplified optimization problem:
Despite its more complex appearance, this problem is no more complicated than Eq. 12. Solving this problem will correct peak intensities by removing the bias induced by the previously used l1 penalty.
Boundary conditions
There is a possible improvement of the method concerning boundary conditions. As Eq. 2 suggests, a strong μ penalty forces the baseline to be constant. In Fig. 2 we see that this phenomenon is especially present at the domain boundaries.

The boundary problem and its correction The green curve is the baseline x b as computed by Eq. 2, the blue curve is the baseline \(\tilde {x}_{b}\) after boundary condition correction
We solved this problem by imposing baseline values at boundaries. This corrected solution is also shown in Fig. 2 and we can see that the corrected solution does not suffer from boundary effect anymore. Appendix “Boundary correction”, page 11, provides all the details on how to modify Eqs. 9 and 13 to introduce some constraints on the baseline values x b . These modified equations will constitute our final model formulation.
Final model formulation
After boundary correction, the modified Eq. 9 is
and the modified Eq. 10 is
The solution \(\widehat {\mathbf {x}}_{p}\) is the unique minimizer of \(\widetilde {\mathcal {J}}_{2}\) subject to positivity constraint:
The gradient is obtained by a straightforward computation:
As before, \(\widehat {\mathbf {x}}_{b}\) is computed from \(\widehat {\mathbf {x}}_{p}\) using Eq. 18. The explicit forms of \(\widetilde {\mathbf {B}}_{\mu }\), \(\widetilde {\mathbf {y}}\) and \(\widetilde {\mathbf {A}}_{\mu }\) are given in Appendix “Boundary correction”, respectively by Eqs. 31, 32 and 33.
Algorithm summary
For ease of reading Algorithm 1 recapitulates the main steps of the proposed method in its final formulation. The optimization procedure used to solve efficiently the two minimization problems will be described in detail in the next section.

Effective minimization
Quadratic programming with bound constraints
To solve the optimization problems Eq. 12 or Eq. 20 and their associated debiasing step Eq. 17 we use the projected Barzilai-Borwein method described in [30]. The Barzilai-Borwein method [31] dramatically improves the classical steepest descent with Cauchy step.
For a convex quadratic form
the steepest descent direction is defined by
with
The associated Cauchy step is defined by
A straightforward calculation leads to:
The Barzilai-Borwein method uses the same steepest descent direction but replaces the Cauchy step by one (or an alternating sequence) of the two so-called Barzilai-Borwein steps. These step lengths are defined by [30]:
Despite its simple update formula the Barzilai-Borwein method works surprisingly well [32, 33]. This method has no line search and exhibits a non-monotonic convergence. It has been shown to be globally convergent for the strictly convex quadratic case [34]. A direct extension to the constrained case is obtained by replacing the iterate x(k+1) by its projection on the feasible domain:
For bound constraints x∈ [ l,u] the projection operator P is simply defined (in a component wise fashion) by
Without any line search [30] gives a counter-example where this method is not convergent. However in practice the method is generally successful, especially for badly conditioned problems where it can outperform the constrained conjugate gradients algorithm [35].
For its simplicity and good behavior in practice we have chosen to use this method. Our implementation is given in pseudo-code in Algorithm 2.

Variants of this method with non-monotone line search [36, 37] have been tested. Theoretically this allows to prove global convergence, but in practice we have observed a performance degradation compared to the simpler method presented in [30].
Stopping criterion
Algorithm 2 stopping criterion needs to be defined. We use a rigorous one based on Karush-Kuhn-Tucker (KKT) conditions [38]. For a smooth convex optimization problem
necessary and sufficient conditions are:
-
1
Stationarity \(\nabla _{\mathbf {x}_{p}} \mathcal {F}+\mathbf {\lambda }^{\mathbf {u}}-\mathbf {\lambda }^{\mathbf {l}}=\mathbf {0}\)
-
2
Primal feasibility \(\mathbf {x}_{p} \in \left [\mathbf {l},\mathbf {u}\right ]\)
-
3
Dual feasibility
-
Lower bounds λl≥0
-
Upper bounds λu≥0
-
-
4
Complementary slackness
-
Lower bounds \(\forall i,\ \mathbf {\lambda }^{\mathbf {l}}\left [i\right ](\mathbf {l}\left [i\right ]-\mathbf {x}_{p}\left [i\right ])=0\)
-
Upper bounds \(\forall i,\ \mathbf {\lambda }^{\mathbf {u}}\left [i\right ](\mathbf {x}_{p}\left [i\right ]-\mathbf {u}\left [i\right ])=0\)
-
Our stopping criterion reflects KKT conditions violation. Enumerating all possible cases this criterion is computed as follow
with s[ i] defined by:
Illustration of the method
We give in Fig. 3 typical convergence behavior for the proposed method applied to problem Eq. 12 or Eq. 17.

Typical convergence behavior of the PBB algorithm given in Algorithm 2. Alternating between BB1 and BB2 steps leads to faster convergence
We observe the non-monotonic convergence behavior of the Barzilai-Borwein method. As reported by [30], we observe that it is more effective to alternate between BB1 Eq. 22 and BB2 Eq. 23 steps than using only one type of step update.
Results and discussion
Synthetic data
The presented algorithm has been tested on synthetic data. The synthetic spectra consist of y vectors of n=500 components. Each y is generated by summing contributions from a synthetic baseline x b , a synthetic peak list x p convolved by a Gaussian peak shape p and a Gaussian noise ε:
The detailed description of these three contributions follows.
-
Synthetic baseline
The analytic expression of the baseline is
$$\mathbf{x}_{b}\left[i\right] = C(s)+s\exp{\left(-3\frac{i}{n}\right)}-2\frac{i}{n} $$where s can take one of the following values s=−1,0,or 1.
For s=0 the baseline is a straight line, for s=−1 the baseline is concave, for s=+1 it is convex.
The constant C(s) insure a positive spectrum. Its value is C(s)=5 for s=1 and C(s)=2 otherwise.
-
Synthetic peak list
The analytic expression of the peak list contribution is:
$$\left(\mathbf{x}_{p}\ast p\right)[\!i]=\sum\limits_{k=1}^{n_{p}}\alpha_{k} p\left(\mu_{k},\sigma_{p},i\right) $$where we have taken n p =10 and
$$p\left(\mu_{k},\sigma_{p},i\right)= \exp{\left(-\frac{1}{2}\left(\frac{i-\mu_{k}}{\sigma_{p}}\right)^{2}\right)} $$These n p Gaussian peaks are defined by a constant shape factor σ p =10. The individual heights α k and centers μ k are tabulated in Table 1.
Table 1 True peak centers μ k and intensities α k . All peaks have a common shape factor σ p =10 -
Simulated zero mean Gaussian noise
The noise ε follows a Normal law of zero mean and σ noise standard deviation:
$$\mathbf{\epsilon}[\!i] \sim \mathcal{N}\left(0,\sigma_{noise}\right) $$
Algorithm implementation
We provide a reference implementationFootnote 1 that can be used to reproduce the results of the following sections. This implementation is coded in C++ and runs under Linux. The main page of the project details all the steps to reproduce the results of the “Joint baseline computation-peak deconvolution”, “Comparison with the usual sequential approach” and “Real data” sections. Typical run-times are one second for the synthetic data and three seconds for the examples using real spectra data. To keep this implementation as simple as possible a basic projected gradient descent is used instead of the more effective Algorithm 2. Also note that this implementation requires CSV input files. A more versatile version of our algorithm, using Algorithm 2, is used in [39]. However, this implementation is not yet publicly available.
Joint baseline computation-peak deconvolution
As explained in “Final model formulation” section, page 8, the joint baseline computation and peak deconvolution is performed in two steps:
-
1
a first resolution of Eq. 20 is performed with a strong λ1 penalty. The role of this step, is to obtain peak centers from the noisy spectrum. This set of peak centers is denoted by Ω. This step is illustrated in Figs. 4 and 5.
Fig. 4 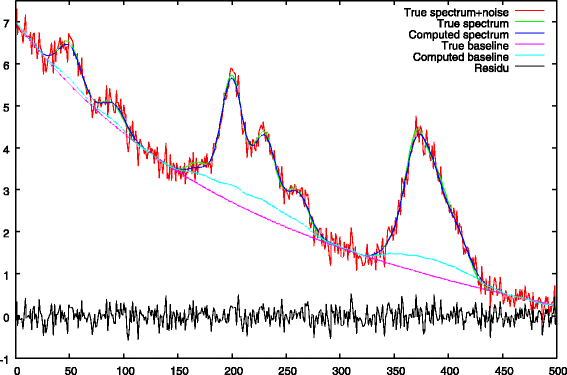
Step 1: first baseline approximation with λ1>0, comparison between the true baseline. We notice an ascent of the baseline under the peaks
Fig. 5 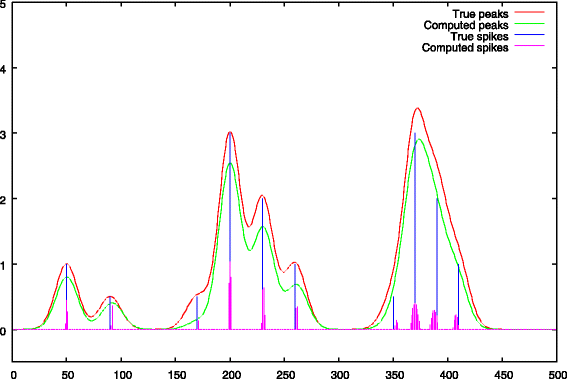
Step 1: peak selection, comparison between the true peak support and the deconvolved peaks. The negative impact of a strong λ1 penalty is showed, the peak heights are underestimated
-
2
a second resolution, is then performed with a null λ1 penalty. This penalty is replaced by the restricted support Ω for peak centers we found in the first step. The role of this step is to correct peak heights and baseline values which were biased by the presence of the strong λ1 penalty of the first step. Illustrations are given in Figs. 6 and 7.
Fig. 6 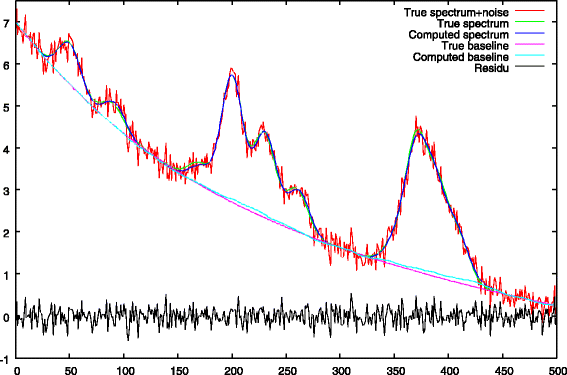
Step 2: final baseline approximation with λ1=0 and Ω peak support regularization. The baseline under the peaks has been corrected
Fig. 7 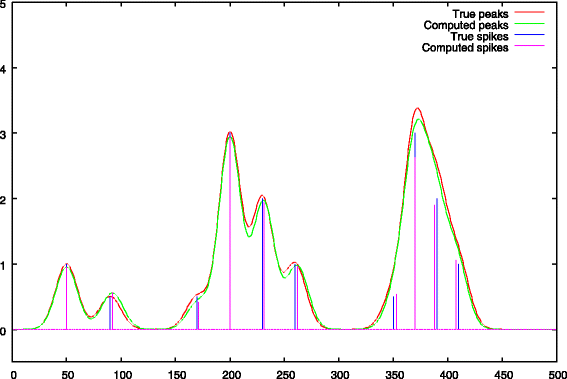
Step 2: peak debiasing, comparison between the true peak support and the deconvolved peaks




The baseline approximation obtained at the end of the first step is given in Fig. 4. This figure shows a common flaw of most of the baseline removal methods which is an ascent of the baseline under the peaks.
The deconvolved peaks obtained after the first step are given in Fig. 5. We notice the negative impact of a strong λ1 penalty which leads to an underestimation of the peak heights. The figure also shows that the deconvolved solution is less spiky in regions of strong peak overlaps (right part of the spectrum).
The baseline computed after the second step is shown in Fig. 6. During this second stage, the λ1 penalty is removed and replaced by a restricted support Ω computed using Eq. 16. We see that the ascent of the baseline under the peaks has been corrected (c.g. x-axis ranges from 150 to 250 and from 350 to 400).
The new peak heights are shown in Fig. 7. The main role of this second stage is to debias peak heights. Compared to Fig. 5 we can see that this objective is quite well fulfilled.
Comparison with the usual sequential approach
In this second part we provide a comparison between our new method and a common procedure used to extract peaks. The objective is to validate the approach and to see if there are some advantages to use the joint baseline computation and peak deconvolution over more traditional approaches. Our method essentially depends on 3 hyper-parameters λ1,λ2 and μ. The parameter λ2 is of minor importance and is constantly set to 0.1. The two other hyper-parameters are:
-
1
the λ1 parameter enforcing the sparsity of the solution x p ,
-
2
the μ parameter enforcing the smoothness of the baseline x b .
In order to perform a fair comparison with another approach we tried to stick to an approach that also only uses two hyper-parameters. The usual approaches in spectra processing generally chain at least two procedures [4]. In peculiar, the baseline subtraction procedure is followed by a peak picking procedure.
-
1
Baseline subtraction: the Statistics-sensitive Non-linear Iterative Peak-clipping (SNIP) algorithm [40–42] is an efficient algorithm to compute spectrum baseline. It generally gives good results and is easy to implement. It uses only one parameter, the window width mSNIP, but requires a smoothed spectrum. To smooth the spectrum we use a Savitzky-Golay filter [6, 7]. The idea is to locally fit the spectrum by a polynomial. This least-squares fitted polynomial of degree d is computed using mSG points of a running window. For each window position, the spectrum value at the window center is then replaced by the polynomial value. In order to have only one parameter, a fixed window width mSG=39 is used for the smoothing step.
-
2
Peak picking: once the baseline has been subtracted from the original spectrum, there are a large panel of methods to extract peaks [4]. We can mention simple thresholding [42], second derivative computation using Savitzky-Golay filters, extraction from wavelet coefficients or deconvolution. For our comparison we are more interested by deconvolution-like methods [21, 22] which are closer to our approach. By consequence we have decided to extract peaks thanks to the usual sparse deconvolution problem:
$$ \arg\min\limits_{\mathbf{x}_{p}\ge0} \frac{1}{2}\big\|\mathbf{y} - \mathbf{L}\mathbf{x}_{p}\big\|^{2}_{2} + \lambda_{1} \big\|\mathbf{x}_{p}\|_{1} + \frac{\lambda_{2}}{2} \big\|\mathbf{x}_{p}\big\|_{2}^{2} $$(26)As for our method, the coefficient λ2 is not critical and we set it to a constant value λ2=0.1. The remaining λ1 is our second free parameter. To solve Eq. 26 we use the same Barzilai-Borwein solver, detailed in Algorithm 2 and the same two-steps procedure which consists in peak selection (high λ1) and peak heights debiasing (λ1=0).
To compare the two approaches we perform a systematic grid search for the two hyper-parameters. The grid for our new method is given Table 2, whereas Table 3 is used by the usual method, that sequentially removes the baseline and then performs the peak deconvolution.
For each processed spectrum we perform a systematic parameter grid search and report the best result obtained by the two methods. To find the best solution we compare the deconvolved peaks with the ground truth of our synthetic data. We use the following procedure to compare these two peak lists. As defined in our model, a peak list is stored in a sparse vector x p . To each nonzero component \(\mathbf {x}_{p}\left [i\right ]\) corresponds a peak at position i and height \(x_{p}\left [i\right ]\). Like computed peak centers and ground truth peak centers might not be perfectly aligned we reconstruct a continuous signal by convolving the two peak lists by the known peak shape p. This blurring is required later to compute the Euclidean distance between these two peak lists. This reconstruction is performed by the following matrix-vector products: \(L\mathbf {x}_{p}^{\star }\) for the ground truth peak list and \(L\hat {\mathbf {x}}_{p}\) for the peaks extracted by the algorithm. Using these vectors we can now compute a normalized Euclidean distance defined by:
For each noise level and each algorithm the computations are performed 10 times, each time with a different noise realization. From these 10 replica we report the obtained mean and standard deviation of the \(\mathcal {E}_{e}\) merit factor. The results are given in Table 4 and plotted in Fig. 8.

Box plot of the results presented in Table 4. \(\mathcal {E}_{e}\) merit factor, lower is better
On this example the joint evaluation of the baseline and of the deconvolved peaks outperforms the sequential approach in nearly all configurations except for the noise-free case. In this condition, as we are using synthetic data, a perfect reconstruction of the “ground truth” spectrum is possible. By consequence, the reconstruction error is very small. To explain this result, we think that our iterative solver had stopped its iterative resolution too early.
To get more intuition on what is happening we provide Fig. 9 illustrating the baseline computation using the SNIP algorithm.

Details of the Savitzky-Golay smoothing + SNIP baseline, σ noise =1,mSNIP=28. The baseline removal can introduce serious artifacts. In a sequential approach these artifacts directly affect the peak picking algorithm
As explained the SNIP algorithm needs to work on a previously smoothed spectrum. This smoothing is performed using a Savitzky-Golay filter. This sequential approach, smoothing then SNIP baseline, can introduce an important bias on the computed baseline. This error is then transferred to the peak picking algorithm. The result can be a poor peak extraction.
Baselines obtained by our method and by the classical SNIP algorithm are shown in Fig. 10.

Computed baselines comparison. The blue curve is the baseline obtained by our method whereas the black one is the baseline computed by the SNIP algorithm. Our method is able the recover a nearly exact baseline unlike the usual one that presents artifacts and ascent below peaks. This result is for σ noise =1, s=−1 (convex baseline) and parameters given in Table 4
We see that the simultaneous baseline and deconvolution approach allows a nearly perfect reconstruction of the baseline. Unlike our approach, the SNIP algorithm suffers from initial filtering of the spectrum and presents baseline ascent below peaks.
Real data
We present some results obtained by our algorithm on real MALDI-ToF mass spectra. The Fig. 11 shows the peaks obtained when the low resolution spectrum is deconvolved with a tight peak shape. We have used a Gaussian peak shape with σpeak=0.4 m/z. The goal is to evaluate the behavior of the algorithm when we try to deconvolve isotopic motifs. The notable result here is to see that the returned peak centers are approximately spaced by 1 m/z which is the expected value. This result is encouraging as this information was not provided to the algorithm to perform its deconvolution.

Low resolution MALDI-ToF spectrum, isotopic motifs deconvolution obtained for tight Gaussian peak shape of σpeak=0.4 m/z
However isotopic motif deconvolution without using any extra information (like an expected 1 m/z spacing between peaks) can lack robustness. That is the reason why it is certainly safer to use a wider peak shape to model the unresolved isotopic motif as a whole. This is illustrated by Fig. 12. We have run the algorithm twice. The first run used a sparsity promoting regularization of λ1=1, the second run used λ1=0.5.

Low resolution MALDI-ToF spectrum, deconvolution obtained when considering unresolved isotopic motifs as an unique peak. The Gaussian peak shape is σpeak=2 m/z. The regularization is λ1=1 for the top plot and λ1=0.5 for the bottom one
The developed algorithm can also be used with high resolution MALDI-ToF mass spectrum (reflectron mode). Figure 13 gives such an example. A Gaussian peak shape with σpeak=0.15 m/z is used for the deconvolution. As before, we have used two values for the sparsity promoting regularization. The first run used λ1=0.5, the second run used λ1=0.2. We clearly see the impact on the results, in the first case only the main peaks are extracted, in the second one very small peaks are also extracted. For the moment this λ1 parameter has to be manually tuned by the user.

High resolution MALDI-ToF spectrum, peak extraction with a Gaussian peak shape of σpeak=0.15 m/z. The regularization is λ1=0.5 for the top plot and λ1=0.2 for the bottom one
It is generally quite difficult to evaluate peak picking methods on real spectra because we do not have the ground truth at our disposal. However, in our case we have expensively used the proposed approach in the BHI-PRO project. The study [39] compares our method against a more usual one on mass spectra of spiked proteins. This study quantifies the algorithmic part of the variance of the measured protein abundances and shows a clear gain in favor of our algorithm.
Conclusions
We have introduced a new method for peak deconvolution. This new approach jointly performs baseline computation and peak deconvolution. The baseline equation can be solved in a closed form and is substituted into the deconvolution equation. The new deconvolution equation contains a linear operator A μ acting as a smoothed second order derivator. The problem of boundaries is exposed and tackled rigorously leading to a modified equation. The problem is efficiently solved by the projected Barzilai-Borwein algorithm. A comparison with a traditional approach relying on a sequential baseline removal and peak picking is detailed. The benefits of our new approach are put in evidence, including a better baseline approximation avoiding ascent below the large peaks, and a better reconstruction of the deconvolved peaks. Finally the method has been tested on real data.
Perspectives
There are two main directions we want to explore. The first direction is to go one step further in a joint processing approach by allowing automatic adjustment of the peak shape function. Ideally, with such an approach, the baseline, the peak shape and the deconvolved peaks would be computed jointly. The second direction would be to devise a procedure for automatic tuning of the two main hyper-parameters. The resulting algorithm would be of great value to process a large number of spectra in batch mode.
Appendix
Smoothness and convolution matrix
To enforce baseline x b smoothness the first order finite differences matrix D of dimension (n−1)×n
has been introduced. For ease of reading we also provide the DtD matrix expression. Its dimension is n×n and its components are:
The matrices DtD and \(\mathbf {B}_{\mu }=\mathbf {I}_{b}+\mu \mathbf {D}^{t}\mathbf {D}\) are tridiagonal matrices. Hence the associated matrix-vector products can be computed efficiently. The Thomas algorithm [43], which is a Gaussian elimination optimized for tridiagonal matrices, also provides an efficient way to compute the matrix-vector products associated to the \(\mathbf {A}_{\mu }= \mathbf {I}_{b}-\mathbf {B}_{\mu }^{-1}\) operator.
In the presentation the convolution product between the peak list and peak shape function, x p ∗p, is often represented by the Lx p matrix-vector product. However, in practical computations the L matrix is never explicitly formed and the convolution product is computed directly using a specialized subroutine.
Derivation of reduced objective
This appendix focuses on the reduced criterion Eq. 10.
Let φ be a function which takes as input a vector z of size n and produces as output the scalar quantity
where q0 is a scalar, q is a vector of size n and Q is a strictly positive-definite symmetric matrix of size n×n. The minimizer of φ is \(\hat {\mathbf {z}} = -\mathbf {Q}^{-1}\mathbf {q}\) and the minimum is
If we introduce the gradient ∇φ(z)=Qz+q and the Hessian ∇2φ(z)=Q we notice that the previous relation takes the following form:
If we consider Eq. 6 as a function of x b
where
and
then application of Eq. 27 directly leads to Eq. 10:
with a constant term \(\mathbf {C}=-\frac {1}{2}\mathbf {y}^{t} \mathbf {A}_{\mu } \mathbf {y}\).
Expression of \(\underset {\mu \rightarrow \infty }{\lim } \mathbf {A}_{\mu }\)
The matrix DtD is real and symmetric, hence it admits an eigen decomposition
where Δ is a diagonal matrix of eigenvalues ν k and V is an orthonormal matrix. Each column k of V is an eigenvector v k .
Let’s write down two basic statements about eigenpair \(\left (\nu,\mathbf {v}\right)\) of any square matrix M:
- the first one, where I denotes the identity matrix, is:
- the second one, that requires M to be invertible (hence ν≠0), is:
Now observe that like \(\mathbf {I}_{b}+\mu \mathbf {D}^{t}\mathbf {D}\) is a strictly diagonally dominant matrix it is invertible [44]. Using the two previously enumerated relations it is easy to show that this matrix admits the following eigen decomposition:
By construction (first order finite differences) the product of the matrix D with a constant vector is the null vector. It follows that we have \(\mathbf {D}^{t}\mathbf {D}\,\mathbf {v}_{1}=\mathbf {0}\) where \(\mathbf {v}_{1}=\frac {1}{\sqrt {n}}\mathbb {1}_{n}\). Thus v1 is the normalized eigen vector associated to the ν1=0 eigenvalue. Moreover, as DtD is an unreducedFootnote 2 real symmetric tridiagonal matrix, all its eigenvalues are simples ([45], Lemma 7.7.1). By consequence we can write:
with ν k ≠0 for all k≥2. It is then trivial to compute the limit:
which is a square matrix of dimensions n×n with all entries equal to 1.
From the definition of A μ in Eq. 11 we get the expected result:
with δi,j equals to 1 if i=j and 0 otherwise.
Boundary correction
Our boundary correction approach exploits the opportunity to convert an equality constrained problem
into a unconstrained modified problem
Let begin by writing the Lagrangian [38] associated to Eq. 28.
The KKT conditions are then easily obtained by differentiating the Lagrangian and by imposing constraint satisfaction:
where λ k is the Lagrangian multiplier associated to the constraint \(\mathbf {x}[k]=\bar {y}_{k}\) and e k the vector of component δ k (i). We can expand the \(\nabla _{\mathbf {x}} \mathcal {L}(\mathbf {x},\lambda _{k})=0\) equation to get:

It is then obvious that if we take:
then the constraint \(\mathbf {x}[k]=\bar {y}_{k}\) is fulfilled. Substituting this into the \(\nabla _{\mathbf {x}} \mathcal {L}(\mathbf {x},\lambda _{k})=0\) equation we get:

This equation is usable but its drawback is that we have lost the symmetry of the modified Q matrix. This can be fixed by another modification of the vector term q. Exploiting the fact that by construction \(\mathbf {x}[\!k]=\bar {y}_{k}\) we have the following equivalent system:

By identification we can write down the announced result:
which is an unconstrained system for which the minimizer satisfies \(\mathbf {x}\left [k\right ]=\bar {y}_{k}\). For presentation clarity we only have considered one constraint, but this scheme can be used sequentially for any set of constraints
Now we can see how to use this technique to our deconvolution problem. We must go back to Eq. 8:
By identification the role of the matrix Q is played by the B μ matrix. Furthermore all the modifications done on the vector q can be transposed to modifications associated to the −y vector.
As an illustrative example, we consider the most usual case that consists of imposing the left \(\bar {y}_{1}\) and right \(\bar {y}_{n}\) baseline values at boundaries. Direct application of Eq. 30 provides the result. The modified B μ matrix is:
The modified y vector is:
With these modifications, the modified Eq. 9 that allows to retrieve the baseline x b from the deconvolved peaks x p is now:
The modified A μ operator Eq. 11 is computed as before
The final quadratic form Eq. 13 must be replaced by:
Notes
No off-diagonal element is null
Abbreviations
- BB:
-
Barzilai-Borwein
- BHI-PRO:
-
Bayesian hierarchical inversion for mass spectrometry. Application to discovery and validation of new PROtein biomarkers
- CWT:
-
Continuous wavelet transform
- DWT:
-
Discrete wavelet transform
- KKT:
-
Karush-Kuhn-Tucker
- LC:
-
Liquid chromatography
- MALDI-ToF:
-
Matrix-assisted laser desorption/ionization-time of flight
- MS:
-
Mass spectrometry
- SG:
-
Savitzky-golay
- SNIP:
-
Statistics-sensitive non-linear iterative peak-clipping
- UDWT:
-
Undecimated wavelet transform
References
van Belkum A, Welker M, Pincus D, Charrier JP, Girard V. Matrix-assisted laser desorption ionization time-of-flight mass spectrometry in clinical microbiology: What are the current issues?Ann Lab Med. 2017; 37(6):475.
Ilina EN, Borovskaya AD, Malakhova MM, Vereshchagin VA, Kubanova AA, Kruglov AN, Svistunova TS, Gazarian AO, Maier T, Kostrzewa M, Govorun VM. Direct bacterial profiling by matrix-assisted laser desorption-ionization time-of-flight mass spectrometry for identification of pathogenic neisseria. J Mol Diagn. 2009; 11(1):75–86.
Singhal N, Kumar M, Kanaujia PK, Virdi JS. Maldi-tof mass spectrometry: an emerging technology for microbial identification and diagnosis. Front Microbiol. 2015; 6:791. https://doi.org/10.3389/fmicb.2015.00791.
Yang C, He Z, Yu W. Comparison of public peak detection algorithms for maldi mass spectrometry data analysis. BMC Bioinformatics. 2009; 10(1):4.
Larive CK, Sweedler JV. Celebrating the 75th anniversary of the acs division of analytical chemistry: A special collection of the most highly cited analytical chemistry papers published between 1938 and 2012. Anal Chem. 2013; 85(9):4201–2.
Savitzky A, Golay MJ. Smoothing and differentiation of data by simplified least squares procedures. Anal Chem. 1964; 36(8):1627–39.
Gorry PA. General least-squares smoothing and differentiation by the convolution (savitzky-golay) method. Anal Chem. 1990; 62(6):570–3.
Browne M, Mayer N, Cutmore TR. A multiscale polynomial filter for adaptive smoothing. Digit Signal Process. 2007; 17(1):69–75.
Barak P. Smoothing and differentiation by an adaptive-degree polynomial filter. Anal Chem. 1995; 67(17):2758–62.
Shensa MJ. The discrete wavelet transform: wedding the a trous and mallat algorithms. IEEE Trans Signal Process. 1992; 40(10):2464–82.
Nason GP, Silverman BW. The stationary wavelet transform and some statistical applications In: Antoniadis A, Oppenheim G, editors. Wavelets and Statistics. New York: Springer: 1995. p. 281–99. https://doi.org/10.1007/978-1-4612-2544-7_17.
Coombes KR, Tsavachidis S, Morris JS, Baggerly KA, Kuerer HM. Improved peak detection and quantification of mass spectrometry data acquired from surface-enhanced laser desorption and ionization by denoising spectra with the undecimated discrete wavelet transform. Proteomics. 2005; 5:4107–17.
Antoniadis A, Bigot J, Lambert-Lacroix S. Peaks detection and alignment for mass spectrometry data. J Société Française Stat. 2010; 151(1):17–37.
Perez-Pueyo R, Soneira MJ, Ruiz-Moreno S. Morphology-based automated baseline removal for raman spectra of artistic pigments. Appl Spectrosc. 2010; 64(6):595–600.
Morháč M, Matoušek V. Peak clipping algorithms for background estimation in spectroscopic data. Appl Spectrosc. 2008; 62(1):91–106.
Mazet V, Carteret C, Brie D, Idier J, Humbert B. Background removal from spectra by designing and minimising a non-quadratic cost function. Chemometr Intell Lab Syst. 2005; 76(2):121–33.
Ruckstuhl AF, Jacobson MP, Field RW, Dodd JA. Baseline subtraction using robust local regression estimation. J Quant Spectrosc Radiative Transf. 2001; 68(2):179–93.
Li Z, Zhan DJ, Wang JJ, Huang J, Xu QS, Zhang ZM, Zheng YB, Liang YZ, Wang H. Morphological weighted penalized least squares for background correction. Analyst. 2013; 138(16):4483–92.
Dubrovkin J. Evaluation of the peak location uncertainty in second-order derivative spectra. Case study: symmetrical lines. J Emerg Technol Comput Appl Sci. 2014; 3:9.
Mohammad-Djafari A, Giovannelli JF, Demoment G, Idier J. Regularization, maximum entropy and probabilistic methods in mass spectrometry data processing problems. Int J Mass Spectrom. 2002; 215(1):175–93.
Renard BY, Kirchner M, Steen H, Steen JA, Hamprecht FA. Nitpick: peak identification for mass spectrometry data. BMC Bioinformatics. 2008; 9(1):355.
Slawski M, Hussong R, Tholey A, Jakoby T, Gregorius B, Hildebrandt A, Hein M. Isotope pattern deconvolution for peptide mass spectrometry by non-negative least squares/least absolute deviation template matching. BMC Bioinformatics. 2012; 13(1):291.
Giovannelli JF, Coulais A. Positive deconvolution for superimposed extended source and point sources. Astron Astrophys. 2005; 439:401–12.
Hirsch M, Schölkopf B, Habeck M. A blind deconvolution approach for improving the resolution of cryo-em density maps. J Comput Biol. 2011; 18(3):335–46.
Lange E, Gröpl C, Reinert K, Kohlbacher O, Hildebrandt A. High-Accuracy Peak Picking Of Proteomics Data Using Wavelet Techniques. In: Biocomputing 2006. World Scientific: 2012. p. 243–54. https://www.worldscientific.com/doi/abs/10.1142/9789812701626_0023.
Du P, Kibbe WA, Lin SM. Improved peak detection in mass spectrum by incorporating continuous wavelet transform-based pattern matching. Bioinformatics. 2006; 22(17):2059–65.
Mallat S, Zhong S. Characterization of signals from multiscale edges. IEEE Trans Pattern Anal Mach Intell. 1992; 7:710–32.
Figueiredo MA, Nowak RD, Wright SJ. Gradient projection for sparse reconstruction: Application to compressed sensing and other inverse problems. IEEE J Sel Top Sign Process. 2007; 1(4):586–97.
Tibshirani R. Regression shrinkage and selection via the lasso. J R Stat Soc Ser B Methodol. 1996; 58(1):267–88. http://www.jstor.org/stable/2346178.
Dai YH, Fletcher R. Projected barzilai-borwein methods for large-scale box-constrained quadratic programming. Numer Math. 2005; 100(1):21–47.
Barzilai J, Borwein JM. Two-point step size gradient methods. IMA J Numer Anal. 1988; 8(1):141–8.
Fletcher R. On the barzilai-borwein method In: Qi L, Teo K, Yang X, editors. Optimization and Control with Applications. Boston: Springer US: 2005. p. 235–56.
Raydan M. The barzilai and borwein gradient method for the large scale unconstrained minimization problem. SIAM J Optim. 1997; 7(1):26–33.
Raydan M. On the barzilai and borwein choice of steplength for the gradient method. IMA J Numer Anal. 1993; 13(3):321–6.
Moré JJ, Toraldo G. On the solution of large quadratic programming problems with bound constraints. SIAM J Optim. 1991; 1(1):93–113.
Kim D, Sra S, Dhillon IS. A non-monotonic method for large-scale non-negative least squares. Optim Methods Softw (OMS). 2012.
Birgin EG, Martínez JM, Raydan M. Nonmonotone spectral projected gradient methods on convex sets. SIAM J Optim. 2000; 10(4):1196–211.
Boyd S, Vandenberghe L. Convex optimization.Cambridge university press; 2009.
Mercier C, Klich A, Truntzer C, Picaud V, Giovannelli J-F, Ducoroy P, Grangeat P, Maucort-Boulch D, Roy P. Variance component analysis to assess protein quantification in biomarker discovery. application to MALDI-TOF mass spectrometry. Biom J. 2017; 60(2):262–74. https://doi.org/10.1002/bimj.201600198.
Ryan C, Clayton E, Griffin W, Sie S, Cousens D. Snip, a statistics-sensitive background treatment for the quantitative analysis of pixe spectra in geoscience applications. Nucl Inst Methods Phys Res Sec B: Beam Interactions with Mater Atoms. 1988; 34(3):396–402.
Morháč M, Kliman J, Matoušek V, Veselskỳ M, Turzo I. Background elimination methods for multidimensional coincidence γ-ray spectra. Nucl Inst Methods Phys Res Sec A: Accelerators, Spectrometers, Detectors and Assoc Equip. 1997; 401(1):113–32.
Gibb S, Strimmer K. Maldiquant: a versatile R package for the analysis of mass spectrometry data. Bioinformatics. 2012; 28(17):2270–1.
Conte SD, Boor CWD. Elementary numerical analysis: an algorithmic approach: McGraw-Hill High Educ.1980.
Varga RS. Geršgorin and his circles: Springer Berlin Heidelberg; 2004. https://doi.org/10.1007/978-3-642-17798-9.
Parlett BN. The symmetric eigenvalue problem. SIAM. 1980; 7:134.
Acknowledgment
We thank Bruno Lacroix (bioMérieux) and Pierre Mahe (bioMérieux) for their contribution during the ANR Grant submission and execution. We thank Laurent Gerfault (CEA) for his advises for the development of the BHI-PRO MALDI model, data processing and data analysis. We thank Amna Klich, Delphine Maucort-Boulch, Pascal Roy (Biostatistique, Hospices Civils de Lyon) and Patrick Ducoroy (CLIPP) for their advises and comments during the development and tests of the method.
Funding
The BHI-PRO project has been partially funded by the Agence Nationale de la Recherche under grant ANR 2010 BLAN 0313 and by Commisariat à l’Energie Atomique et aux Energies Alternatives (CEA) for CEA authors contribution (VP, PG).
Availability of data and materials
The datasets used to generate the figures and a basic implementation of the proposed algorithm are avalaible under the https://github.com/vincent-picaud/Joint_Baseline_PeakDeconvGitHub repository.
Author information
Authors and Affiliations
Contributions
VP initial idea of the method, theoretical developments and C++ implementation. The contributions of JFG and AG regard (a) the design of the criterion and its optimization and (b) the writing of the paper. CT read and approved the final manuscript and proposed valuable comments about pre-processing of spectra in the context of mass spectrometry. CM participated in the problem definition and evaluated the methods on real spectra. JPC provided input in the MALDI-ToF field and the result interpretation. He acquired and provided real MALDI-ToF spectra to test the algorithm. PG was the BHI-PRO project manager. He has coordinated the conception and design of the processing algorithms, in particular the design of the acquisition chain MALDI and MRM models and inversion algorithms, and the interpretation of the data. He has revised the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable
Consent for publication
Not applicable.
Competing interests
JPC is employed by bioMérieux. The other authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Picaud, V., Giovannelli, JF., Truntzer, C. et al. Linear MALDI-ToF simultaneous spectrum deconvolution and baseline removal. BMC Bioinformatics 19, 123 (2018). https://doi.org/10.1186/s12859-018-2116-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12859-018-2116-3