- Research
- Open access
- Published:
ncDENSE: a novel computational method based on a deep learning framework for non-coding RNAs family prediction
BMC Bioinformatics volume 24, Article number: 68 (2023)
Abstract
Background
Although research on non-coding RNAs (ncRNAs) is a hot topic in life sciences, the functions of numerous ncRNAs remain unclear. In recent years, researchers have found that ncRNAs of the same family have similar functions, therefore, it is important to accurately predict ncRNAs families to identify their functions. There are several methods available to solve the prediction problem of ncRNAs family, whose main ideas can be divided into two categories, including prediction based on the secondary structure features of ncRNAs, and prediction according to sequence features of ncRNAs. The first type of prediction method requires a complicated process and has a low accuracy in obtaining the secondary structure of ncRNAs, while the second type of method has a simple prediction process and a high accuracy, but there is still room for improvement. The existing methods for ncRNAs family prediction are associated with problems such as complicated prediction processes and low accuracy, in this regard, it is necessary to propose a new method to predict the ncRNAs family more perfectly.
Results
A deep learning model-based method, ncDENSE, was proposed in this study, which predicted ncRNAs families by extracting ncRNAs sequence features. The bases in ncRNAs sequences were encoded by one-hot coding and later fed into an ensemble deep learning model, which contained the dynamic bi-directional gated recurrent unit (Bi-GRU), the dense convolutional network (DenseNet), and the Attention Mechanism (AM). To be specific, dynamic Bi-GRU was used to extract contextual feature information and capture long-term dependencies of ncRNAs sequences. AM was employed to assign different weights to features extracted by Bi-GRU and focused the attention on information with greater weights. Whereas DenseNet was adopted to extract local feature information of ncRNAs sequences and classify them by the full connection layer. According to our results, the ncDENSE method improved the Accuracy, Sensitivity, Precision, F-score, and MCC by 2.08\(\%\), 2.33\(\%\), 2.14\(\%\), 2.16\(\%\), and 2.39\(\%\), respectively, compared with the suboptimal method.
Conclusions
Overall, the ncDENSE method proposed in this paper extracts sequence features of ncRNAs by dynamic Bi-GRU and DenseNet and improves the accuracy in predicting ncRNAs family and other data.
Background
RNAs in organisms can be classified into two main categories, namely, coding RNAs [1] and non-coding RNAs (ncRNAs) [2]. A major difference between these two types of RNAs lies in their protein encoding ability [3]. For instance, messenger RNA (mRNA) in coding RNA [4] can form proteins that are essential for life activities by means of transcription and translation [5]. Although ncRNAs are not directly involved in the formation of encoded proteins, they can guide protein synthesis and indirectly participate in the translation and transcription processes [6]. As human genome annotation has become more sophisticated, researchers have found that only 1-2\(\%\) of all human genes can directly encode proteins [7], however, it is found that at least 76\(\%\) of the genome has the ability to produce transcription products, consequently, a large number of unknown ncRNAs play essential roles in life activities [8]. ncRNAs can be classified according to their structure, function, and coding gene location. The current research hotspots of ncRNAs include microRNAs (miRNAs), long-stranded non-coding RNAs (lncRNAs), ribosomal RNAs (rRNAs) and tRNAs [9]. Of them, miRNAs are the nucleotide sequences approximately 22 nt in length, which can reduce the expression of mRNA by base complementary pairing at the transcriptional level [10]. lncRNAs are ncRNAs greater than 200 nt in length, which are the important component of the non-coding genome. Typically, lncRNAs function to regulate transcribed RNAs and protein translation, and are involved in various regulatory physiological and pathological processes [11]. rRNAs, which are essential for life, play a regulatory role in cells and participate indirectly in protein transcription [12]. Other famous ncRNAs include ribozymes [13] and Intron\(\_\)RNA [14]. Internal ribosome entry sites (IRES [15]), leader [16] and riboswitch [17] belong to mRNA fragments. Notably, ribozymes belong to a class of catalytically active RNA molecules exiting in nature, which can catalyze reactions such as RNA breakage and ligation. Intron\(\_\)RNA is the RNA transcribed from intron genes, after being transcribed into RNA, it can interact with many substances to help link exons together in the correct order. IRES, as an effective translation initiator, is commonly constructed in the middle of ribosome and mRNA. Leader is the upstream segment of the start codon in mRNA, which can regulate mRNA transcription. As for riboswitch, it is a regulatory segment of mRNA, which plays a role in regulating gene expression in prokaryotes.
With the rapid development of high-throughput technology, an increasing number of unknown ncRNAs have been discovered. ncRNAs exert indispensable functions in life activities, so it is important to study the functions of these unknown ncRNAs. Plenty of evidence shows that ncRNAs of the same family have similar functions, therefore, accurately predicting the belonging families of unknown ncRNAs can initially predict the functions of unknown ncRNAs. The traditional method to predict the belonging families of unknown ncRNAs is the bioassay method, but it is labor-intensive and cannot address the large amount of data generated by high-throughput technologies [18]. Therefore, convenient and fast computational methods are applied to predict the ncRNAs families. Computational methods for ncRNAs family prediction can be divided into two types, the first type is to predict based on secondary structure features of ncRNAs, and the second one is to predict according to sequence features of ncRNAs. In the first type, the main workflow is to first predict the secondary structure of ncRNAs, and later predict ncRNAs families based on the secondary structure features of ncRNAs. However, due to the inaccurate ncRNAs secondary structure prediction, there is a lot of useless information in the extracted secondary structure features of ncRNAs, which affects the performance of ncRNA family prediction. The prediction methods based on ncRNAs secondary structure features include GraPPLE [19], RNAcon [20], and nRC [21]. Among them, the GraPPLE method extracts the secondary structure graph information of ncRNAs using summary statistics with local–global properties, and the extracted information is classified by the SVM method afterwards. As for RNAcon, it first distinguishes coding RNAs from ncRNAs by the SVM-based TNC method, and then classifies different ncRNA classes by the RandomForest classifier based on the graph information regarding the secondary structure of ncRNAs. Moreover, the nRC method utilizes the IPknot algorithm to predict RNA secondary structure with pseudoknots, then uses the MoSS decision tree pruning algorithm to obtain substructure, and finally adopts the convolutional neural network as a classifier. The main workflow of the second type of prediction is to directly extract the sequence features of ncRNAs and then perform ncRNAs prediction based on the sequence features of ncRNAs, the main methods are ncRFP [22], ncDLRES [23] and the method proposed by T.M.R. Noviello, F. Ceccarelli et al [24]. With regard to ncRFP, it extracts the ncRNAs sequence features by the RNN model and then classifies them by a fully connected layer. ncRFP simplifies the prediction process and improves the prediction accuracy, however, due to the different lengths of ncRNAs sequences, they are padded or segmented to the same sequence length before LSTM is used to extract features, which not only loses a lot of ncRNAs sequence feature information, but also adds a lot of useless information. ncDLRES makes full use of the ncRNAs sequence features by using dynamic LSTM model, but there are still problems such as low accuracy and low efficiency. In this regard, there is still much room for improvement in ncDLRES performance.The optimal method proposed by T.M.R. Noviello, F. Ceccarelli, M. Ceccarelli et al used 1k-mer method to encode the sequences of ncRNAs, and the encoded ncRNAs sequences were input to a improved CNN model to extract the local features of ncRNAs, which achieved good results, but the method was only applicable to ncRNAs with sequence less than 200 nucleotides. As shown in Fig. 1, the database used in this paper contains ncRNAs with sequences larger than 200 nucleotides, so the ncDENSE method can be used in a broader range.
In this paper, four representative deep learning models, including deep neural networks (DNN), convolutional neural networks (CNN), recurrent neural networks (RNN), and the combination of recurrent and convolutional neural networks (RNN+CNN), were compared. Data in Fig. 2 indicated that the RNN+CNN model was generally superior to the other three models for different lengths of ncRNAs sequences, which was thereby selected for ncRNAs family prediction. The model included the dynamic Bi-GRU, the Attention Mechanism, and the DenseNet, which not only simplified the prediction process but also improved the accuracy compared with the existing methods.

The proportion of different lengths of ncRNAs sequences

Comparison of the accuracy of different deep learning models on different sequence lengths of ncRNAs
Result
ncRNAs include primary structure, secondary structure, and tertiary structure. Of them, the primary structure corresponds to the sequence structure of ncRNAs, while the secondary structure is associated with the planar structure of ncRNAs, and the tertiary structure is related to the spatial structure of ncRNAs [25]. Typically, the primary structure of ncRNAs can be accurately obtained by simple biological experimental methods. Meanwhile, the secondary structure of ncRNAs, which a two-dimensional structure formed by bases in the sequence matching each other through hydrogen bonds, is divided into various forms, including helices and single-stranded. The single-stranded from is further divided into hairpin loop, inner loop, synaptic loop, and multi-branching structure, due to the diversity of secondary structure of ncRNAs, as a result, it is a complex process with a low accuracy in obtaining the secondary structure of ncRNAs. The tertiary structure of ncRNAs is a three-dimensional spatial structure formed by further folding of secondary structure stems, loops, and pseudoknots and other modules. Classical methods for predicting the tertiary structure of ncRNAs are knowledge-based and physical methods, however, due to the instability and easy change by external environmental influences, it is more difficult to directly obtain the tertiary structure of ncRNAs. Sequence structure, planar structure, and spatial structure of ncRNAs contain features of the ncRNAs family, and they can be used as input to the RNN+CNN ensemble deep learning model. The primary structure of ncRNAs has family consistent sequence fragments, therefore, deep learning models can be used to extract ncRNAs sequence features, which can later be used to classify the belonging family of unknown ncRNAs mainly by ncRFP and ncDLRES. Compared with ncRFP, the method proposed in this paper dynamically input the base sequences of ncRNAs into the dynamic Bi-GRU model after encoding, which thus avoided cutting and padding ncRNAs sequences and retaining the full feature information of ncRNAs sequences. Relative to ncDLRES, ncDENSE utilizes Bi-GRU [26, 27] instead of LSTM, which has three gate information while GRU only retains two gate information, thereby significantly improving the code running efficiency. Bi-GRU belongs to the bidirectional RNN model, which not only retains the base information before the current base of ncRNAs sequence, but also records the base information after the current base, contributing to better extracting ncRNAs sequence features. In the ncDLRES method, ResNet [28] is employed to extract the local feature information of ncRNA sequences, and the DenseNet [29] model used in this paper better solved the problem of gradient disappearance when the deep network was back propagated. Compared with the ncRNAs family prediction method by ncRNAs secondary structure, the method proposed in this paper directly skipped the prediction of ncRNAs secondary structure, which not only improved the prediction accuracy but also enhanced the prediction efficiency.
Compared with the previously proposed method, the ncDENSE method was significantly improved in result data in two aspects. The first improvement was reflected in the overall data by comparing data of each method through the average of ten-fold cross-validation, while the second improvement was reflected in the individual ncRNA familiy by comparing the performance of 13 ncRNAs families predicted by different methods.
Comparison of overall data
In the model training process, ten-fold cross-validation was adopted, in which all ncRNAs data were divided into ten parts, with nine of them being used as the training set while the remaining one as the test set in turn, and each model training consisted of 100 epochs. Figure 3 shows the accuracy and loss rate of ncDENSE in the 10th fold cross-validation. As observed, although the curves fluctuated, there was no overfitting or underfitting. The highest model accuracy and lowest loss rate in training were obtained at the epochs of 92. To make the proposed method more convincing, the Accuracy, Sensitivity, Precision, F-score, and MCC of six ncRNAs family prediction methods, namely GeaPPLE, ncRFP, nRC, RNAcon, ncDLRES, and ncDENSE, were compared. Accuracy represented the percentage of correctly predicted ncRNAs among all ncRNAs, Sensitivity indicated the percentage of correctly predicted ncRNAs in each ncRNA family, Precision was the percentage of correctly predicted data for each family, F-score was defined as the weighted average of Sensitivity and Precision, and MCC was the metric used to measure classification performance. Accuracy, Sensitivity, Precision, F-score, and MCC were calculated as follows(Eqs, 1 - 5), with TP, TN, FP, and FN representing True Positives, True Negatives, False Positives, and False Negatives, separately.
Table 1 displays the mean values of the six ncRNAs family prediction methods obtained on the test set by ten-fold cross-validation. In this paper, the proposed ncDENSE method had the best performance in all performance metrics and improved the Accuracy, Sensitivity, Precision, F-score, and MCC by 2.08\(\%\), 2.33\(\%\), 2.14\(\%\), 2.16\(\%\), and 2.39\(\%\), respectively, compared with the suboptimal values.

Accuracy and loss rate of 10-fold cross-validation
Detailed data comparison
This section focused on comprehensively comparing ncRNAs family predictions. To achieve this end, ncRNAs data were divided into 13 categories according to ncRNAs families, including microRNAs, 5 S\(\_\)rRNA, 5.8 S\(\_\)rRNA, ribozymes, CD-box, HACA-box, scaRNA, tRNA, Intron\(\_\)gpI, Intron\(\_\)gpII, IRES, leader and riboswitch. Figure 4 exhibits the Sensitivity, Precision, F-score, and MCC data calculated for each ncRNAs family in the six ncRNAs family prediction methods, including GeaPPLE, ncRFP, nRC, RNAcon, ncDLRES, and ncDENSE. As observed from data in Fig. 4, compared with the other five methods, the ncDENSE method achieved great improvements in MCC, Precision, Sensitivity, and F-Score for the prediction of each ncRNAs family, even though it did not well predict a few ncRNAs families. Figures 5, 6, 7 and 8 present more details of each ncRNA family predicted by the four methods, namely, ncDENSE, ncDLRES, ncRFP, and nRC, in the ten-fold cross-validation. To facilitate observation and comparison, the heat map method was used to record the data in this paper, and the data inside each heat map represents the average of the predicted ncRNAs results of this method by ten-fold cross-validation. The horizontal coordinates represent the predicted results of ncRNAs, and the vertical coordinates represent the true classification of ncRNAs. For example, the row data labeled 5s_rRNA in Figure 4 indicates that 48.2 5s_rRNAs were successfully predicted as 5s_rRNA, 0.1 5s_rRNA was predicted as 5_8s_rRNA, 0.2 5s_rRNA was predicted as tRNA, no 5s_rRNA was predicted as ribozyme, and so on. As discovered from Figs. 5, 6, 7 and 8, the ncDENSE method only predicted two ncRNAs families, 5.8S_rRNA and IRES, with fewer correct predictions of ncRNA family than the ncDLRES method. The number of correctly predicted ncRNAs was improved in other ncRNA families.

Performance comparison of ncRNAs family prediction on different methods

Detailed data of the nRC method for predicting ncRNAs family

Detailed data of the ncRFP method for predicting ncRNAs family

Detailed data of the ncDLRES method for predicting ncRNAs family

Detailed data of the ncDENSE method for predicting ncRNAs family
Time efficiency comparison
This section compares the time efficiency of three ncRNAs prediction methods: ncRFP, ncDLRES, and ncDENSE. ncRFP, ncDLRES, and ncDENSE methods all perform classification prediction of ncRNAs by extracting the sequence features of ncRNAs, because these three methods skip the process of predicting the secondary structure of ncRNAs, so time efficiency of these three methods is much greater than that of the methods that perform classification prediction of ncRNAs by secondary structure features of ncRNAs. ncRFP method uses a model of bidirectional LSTM and full linkage layer, ncDLRES uses a model of LSTM and ResNet, and ncDENSE uses a dynamic Bi-GRU and attention mechanism and DenseNet model. Because LSTM uses three gates to extract features from sequence data while GRU uses only two gates to extract features from sequence data, the operational efficiency of GRU is greater than that of LSTM, and therefore the operational efficiency of the ncDENSE method is greater than that of the ncDLRES method. ncDENSE and ncDLRES methods both use an improved convolutional model to extract local features of ncRNAs sequences, and ncRFP only uses the full concatenation layer for classification, so the ncRFP method runs more efficiently than the ncDENSE method and ncDLRES method. As shown in Figure 9, the running time of ncRFP method is smaller than that of ncDENSE method and ncDLRES method. ncDENSE method is larger than ncDLRES method in terms of running efficiency and accuracy. Although the running efficiency of ncRFP is greater than that of the ncDENSE method, the accuracy of the ncDENSE method is much greater than that of the ncRFP method. We tested the running time of 1264 ncRNAs predictions using a 3090ti graphics card. ncRFP method was only 0.5 s faster than ncDENSE method, but the accuracy of ncDENSE method was 7.15\(\%\) higher than that of ncRFP method. Therefore, by comparing the time efficiency and accuracy of the three methods, the ncDENSE method was superior to the ncRFP method and the ncDLRES method.

Prediction time of ncRNAs by different methods
Discussion
RNAs are the very important biological macromolecules, which play an indispensable role in life activities. RNAs can be divided into two categories based on their protein encoding ability, namely, coding RNAs that can directly participate in protein transcription and translation, and ncRNAs that can indirectly participate in protein translation and transcription. Notably, ncRNAs are associated with structural complexity and functional diversity, which have posed a major obstacle for researchers to unravel their mysteries. In recent years, biologists have made unremitting efforts to find that ncRNAs of the same family have similar functions. Therefore, by identifying the belonging families of unknown ncRNAs, it is possible to initially determine their functions and thus promote the study on ncRNAs. The existing methods used to identify ncRNAs are divided into two categories, namely, biological experiment-based and computational-based methods. Although biological experiment-based methods can achieve high accuracy in some fields, they are labor-intensive and cannot meet the demand for high throughput. Meanwhile, computational-based methods can be further subdivided into two categories, including secondary structure-based and sequence-based characterization of ncRNAs. To be specific, secondary structure-based ncRNAs family prediction methods include RNAcon, GeaPPle, and nRC, but these methods are inefficient because the acquisition of ncRNAs secondary structure involves a complex process with a low accuracy rate. Other methods adopted to classify ncRNAs based on their sequence characteristics are ncRFP and ncDLRES. Of them, the ncRFP method can predict ncRNAs families by sequence features of ncRNAs, which simplifies the prediction process while improving the prediction accuracy compared with RNAcon, GeaPPle, nRC, and other methods. However, this method uses the static LSTM method to fill or intercept the unequal ncRNAs sequences, which may thus miss the characteristic information of some ncRNAs and add some useless characteristic information, thereby decreasing the ncRNAs family prediction accuracy. By contrast, ncDLRES used dynamic LSTM to avoid the problem of missing ncRNAs sequence feature information, nonetheless, it also adopts a one-way RNN model, which can only extract base information before the current base, to extract ncRNAs sequence contextual feature information, resulting in inadequate feature extraction. In this paper, a novel ncDENSE method integrating dynamic BiGRU + Attention Mechanism + DenseNet model was proposed. On the one hand, the dynamic Bi-GRU is improved by not filling or cutting ncRNAs sequences, so that the sequence features of ncRNAs can all be input into the Bi-GRU model. On the other hand, Bi-GRU is a bidirectional RNN model, which retains the base information before the current base and records the base information after the current base, so that the contextual feature information of ncRNAs sequences can be fully extracted. Besides, the Attention Mechanism can assign more weights to the important features of ncRNAs sequences so that attention can be subtly and rationally adjusted to shift, thus ignoring irrelevant information and amplifying important information [30]. Further, DenseNet uses dense connectivity to better solve the problem of back propagation gradient disappearance in deep networks.
Compared with the five previously proposed methods, our proposed ncDENSE method showed great improvements in both the overall data of ncRNAs and the data of individual ncRNAs families. Table 1 displays the mean values of the six methods obtained by ten-fold cross-validation. Clearly, the ncDENSE method improved the Sensitivity, Precision, F-score, and MCC by 3.33\(\%\), 2.12\(\%\), 2.6\(\%\), and 2.39\(\%\), respectively, compared with the suboptimal method. Besides, its Accuracy was improved by 2.57\(\%\) relative to the next best method. Figure 4 displays data comparison results of 13 ncRNAs families between ncDENSE and ncDLRES methods. Apparently, the ncDENSE method outperformed ncDLRES in terms of Sensitivity, Precision, F-score, and MCC on nine ncRNAs families, namely, microRNAs, ribozymes, CD-box, HACA-box, scaRNA, Intron_gpI, Intron_gpII, IRES, leader, and riboswitch. In the 5S_rRNA and tRNA families, the ncDENSE method was only slightly inferior to the ncDLRES method in terms of Precision data; while in the IRES family, only the Sensitivity data obtained by the ncDENSE method were inferior to those of the ncDLRES method. In Figs. 5, 6, 7 and 8, it was found that the nRC method predicted the least number of correct ncRNAs family. All the methods used in Figures 5, 6, 7 and 8 predicted ncRNAs families by the ncRNA sequence features. The numbers of correctly predicted ncRNAs for the ncDENSE method (Fig. 8), ncDLRES method (Fig. 7), and ncRFP method (Fig. 6) were 5490, 5324, and 5009, respectively. Compared with the ncDLRES method, the ncDENSE method did not performed well in predicting 5.8S_RNA and IRES families. Moreover, compared with the ncRFP method, the ncDENSE method does not well predicted the Intron_II family. Therefore, on the whole, the ncDENSE method had significantly enhanced performance in predicting ncRNAs family compared with the other five methods.
Conclusion
The prediction of ncRNAs family can initially determine the functions of ncRNAs. In the face of massive high-throughput ncRNA sequence data, biological experiment-based methods cannot meet the demands for prediction, while the existing main computational methods are associated with the problem of complicated processes and low accuracy. In this paper, a novel computational method for ncRNAs family prediction, ncDENSE, is proposed. In summary, ncDENSE displays four advantages.
First: The ncDENSE method predicts ncRNAs families by extracting sequence features of ncRNAs, which skips the process of obtaining the secondary structure of ncRNAs, improves the ncRNAs family prediction accuracy and simplifies the prediction process.
Second: The ncDENSE method abandons the traditional padding and segmentation of ncRNAs sequences, as a result, the full features of ncRNAs sequences are fully fed into the deep learning model.
Third: The ncDENSE method adopts a bidirectional RNN model-Bi-GRU, which, compared with the unidirectional RNN model, can retains the base information before the current base and records the base information after the current base information, thus facilitating the extraction of ncRNAs sequence contextual features.
Fourth: The ncDENSE method utilizes the DenseNet network to extract local features of ncRNAs sequences, which helps to better mitigate the gradient disappearance of back propagation in the deep networks by dense connectivity.
As for the two ncRNAs families, 5S_RNA and IRES, the ncDLRES method predicts slightly better results than the ncDENSE method. Consequently, the ncDENSE method can be integrated with the ncDLRES method to build the ncRNAs family identification website to provide better help for researchers.
Methods
Data collection and processing
The data processed in this paper were all collected from the Rfam database, which included thirteen ncRNAs families (namely, microRNAs, 5S_rRNA, 5.8S_rRNA, ribozymes, CD-box, HACA-box, scaRNA, tRNA, Intron_gpI, Intron_gpII, IRES, leader and riboswitch), with a total of 6320 pieces of non-redundant ncRNAs data, including 320 pieces of IRES data and 500 of each of the remaining ncRNAs families. ncDENSE used a ten-fold cross-validation method in the model training process, and divided ncRNAs data of each family into ten parts, with nine of them as the training set while the remaining one as the test set in turn. Finally, the results of ten cross-validations were averaged. To input ncRNAs sequences into the ensemble deep learning model, one-hot coding was used to encode the bases of each ncRNA as 1*4, 1*8, and 1*12 data in this paper [31]. A (adenine), U (uracil), G (guanine), and C (cytosine) represent the bases of four common ncRNAs, whose coding rules are shown in Table 2, with “N” representing some rare bases. Figure 10 displays the accuracy of the optimal model trained by each fold of the 10-fold cross-validation on the test set by different coding approaches. Figure 11 shows the average accuracy of the three coding methods in the ten-fold cross-validation. According to the results, the 1*8 coding method was more effective than the 1*4 and 1*12 coding methods, as a result, the 1*8 one-hot coding method was used in ncDENSE to digitally code the bases of ncRNAs sequences, and the length of each ncRNAs sequence after coding was L*8 (L is the base number in ncRNAs sequences).

Accuracy of ten-fold cross-validation with different coding methods

Average cross-validation accuracy of three coding methods with ten folds
Methods
The ncDENSE method utilized an ensemble deep learning model consisting of three components, namely, dynamic Bi-GRU, Attention Mechanism, and DenseNet. Dynamic Bi-GRU is mainly responsible for capturing the long-term dependencies of ncRNAs sequences to extract their contextual feature information. Meanwhile, Attention Mechanism mainly functions to assign different weights to the features extracted by Bi-GRU according to their importance. While DenseNet extracts local features of ncRNAs sequences by dense concatenation. At last, the ncRNAs sequence features extracted by dynamic Bi-GRU, Attention Mechanism, and DenseNet were input to the full-connected layer for ncRNAs family classification. The ncDENSE method proposed in this paper set the number of ncRNAs sequences in each batch to 32. The main working principle of the ncDENSE method is presented in Fig. 12.
-
(1)
Dynamic Bi-GRU
Dynamic Bi-GRU abandons the traditional padding and cutting of ncRNAs sequences, which inputs all base information in ncRNAs sequences of different lengths into Bi-GRU to avoid the loss of base information or the increase in useless information in ncRNAs sequences. Therefore, it prevents the Bi-GRU model from extracting the redundant feature information of ncRNAs sequences or losing the important feature information of ncRNAs sequences. The ncRNAs sequences are data with closely linked contextual information. The bidirectional RNN model can be well applied in extracting the contextual features of ncRNAs sequences by gating information not only to retain the base information before each base but also to record the base information after the current base. The working principle of dynamic Bi-GRU is shown in Fig. 12. GRU is a variant of LSTM, which is simpler than the structure of LSTM and can effectively solve the problem of long dependency in RNN networks. The GRU unit has only two gate information, including update gate and reset gate, which can improve the model’s computing efficiency. The GRU unit structure is schematically shown in Fig. 13, and the operating working principle can be divided into the following four parts.
-
(1)
Calculation of reset gate (green part in Fig. 13 represents the reset door)
The reset gate determines how the new input is combined with the previous information. A larger value of the reset gate represents that it is necessary to remember more information from the previous moment, and that more new input (\(X_{t}\)) is combined with the previous memory (\(h_{t-1}\)). Conversely, a smaller value of the reset gate indicates that less information should be remembered from the previous moment and less new input (\(X_{t}\)) should be combined with the previous memory (\(h_{t-1}\)). The rest gate value can be calculated by Eq. 6.
$$\begin{aligned}&r_{t}=\sigma \left( W_{i r} \cdot X_{t}+b_{i r}+W_{h r} \cdot h_{t-1}+b_{h r}\right) \end{aligned}$$(6)Where \(W_{i r}\) and \(W_{h r}\) are the weight matrices of the reset gate, \(b_{i r}\) and \(b_{h r}\) represent the deviations of the reset gate, \(X_{t}\) is the information input at moment t, \(h_{t-1}\) stands for the information passed in at moment t-1 to moment t, and \(\sigma\) means the activation function sigmoid.
Fig. 12 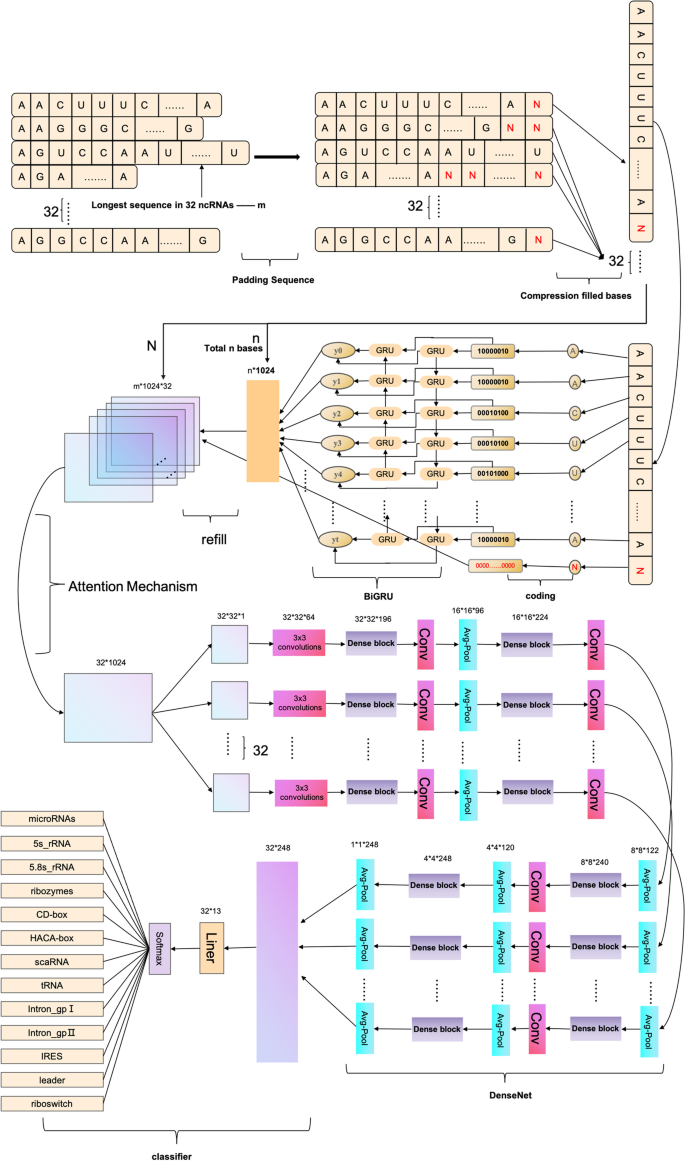
ncDENSE main working process
-
(2)
Calculation of update gate (pink part in Fig. 13 represents the update door) The update gate is used to control the degree to which the state information from the previous moment is brought into the current state. A closer update gate value to 1 indicates that more data are left for the new input, while a value closer to 0 suggests that more new input is forgotten. The update gate value can be calculated by Eq. 7.
$$\begin{aligned}&Z_{t}=\sigma \left( W_{i z} \cdot X_{t}+b_{i z}+W_{h z} \cdot h_{t-1}+b_{h z}\right) \end{aligned}$$(7)Where \(W_{i z}\) and \(W_{h z}\) are the weight matrices of the update gate, \(b_{i z}\) and \(b_{hz}\) are the deviations of the update gate, separately.
-
(3)
Reset of the current memory content
$$\begin{aligned}{\hat{h}}_{t}=\tanh \left( {W_{it}} \cdot {X_{t}}+{b_{it}}+{r_{t}} \cdot \left( {W_{ht}} {h_{t-1}}+b_{ht}\right) \right) \end{aligned}$$(8)Where \(W_{it}\) and \(W_{ht}\) represent the weight matrices, \(b_{it}\) and \(b_{ht}\) are the deviations, and \({\hat{h}}\) represents the information after the current moment of calculation.
-
(4)
GRU output calculation
$$\begin{aligned}&h_{t}=\left( 1-Z_{t}\right) \cdot {{\hat{h}}}_{t-1}+Z_{t} \cdot {\hat{h}}_{t} \end{aligned}$$(9)Where \(h_{t}\) indicates forgetting some information in \({{\hat{h}}}_{t-1}\) passing down from the previous moment and adding some information in \({\hat{h}}_{t}\) of the current moment to form the final memory passed to the next moment.
Fig. 13 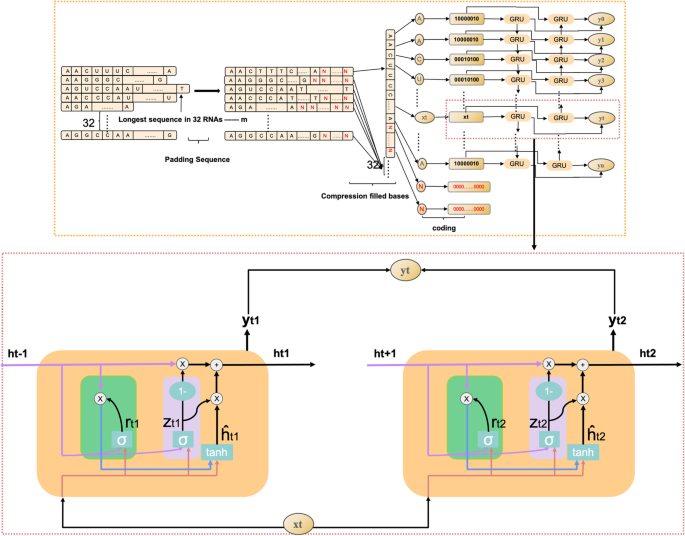
Dynamic Bi-GRU working principle
-
(1)
-
(2)
Attention Mechanism
The core idea of the attention mechanism is to assign more weights to important input information, so that attention can be subtly and rationally shifted to ignore irrelevant information and amplify important information. In this way, the sensitivity of information reception and processing speed in the focused attention area are greatly improved. The attention mechanism works as shown in Eq. 10.
$$\begin{aligned}&C=\sum _{j=1}^{L x} a_{j} h_{j} \end{aligned}$$(10)Where C is the output of the attention mechanism, Lx indicates the length of the input RNA sequence, a suggests the coefficient assigned to the jth hidden state, and h represents the jth hidden state. The attention mechanism is characterized by its ability to well accomplish the task of focusing ncDENSE on the important fragments of the ncRNA family.
-
(3)
DenseNet
The design of DenseNet is inspired by ResNet. A dense connection mechanism is proposed in DenseNet by improving the connection of ResNet. The main idea of the dense connection mechanism is to connect all layers to each other, and each layer receives information from all previous layers as input. In this paper, a 4-layer Dense block was used, and each Dense block had a total of 10 connections, as shown in Fig. 14. The calculation of each layer is shown in Eq. 11.
$$\begin{aligned}&X_{i}=H \quad \left( \left[ X_{1}, X_{2}, X_{3} \ldots \ldots X_{i-1}\right] \right) \end{aligned}$$(11)Where \(X_{i}\) is the result of layer i, and H uses the structure of BN+ReLU+3*3CONV in Eq. 11. Each sequence of ncRNAs is extracted by four dense blocks, and the sizes of the four dense block output features are 32*32*196, 16*16*224, 8*8*240, and 4*4*248, respectively. The transition layer consists of the Conv layer and Avg-Pool layer, which can downscale the features output from the dense block, and the dimensions of three transitions after downscaling are 16*16*96, 8*8*122, and 4*4*120 separately. The size of the last layer of Avg-Pool is 1*1*248, and the last 32 ncRNAs sequences are reshaped together as 32*248 for classification by Liner in PyTorch for the full connection layer.
Fig. 14 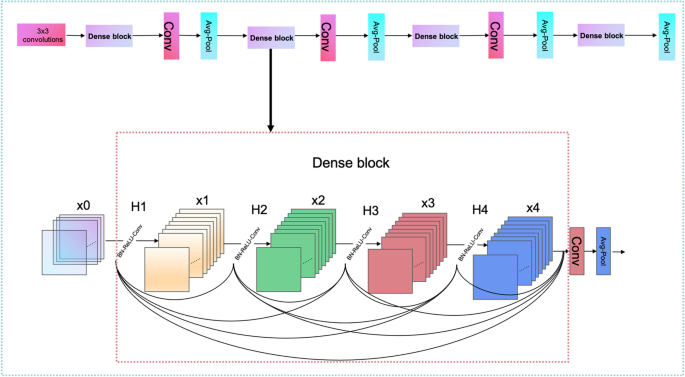
DenseNet’s working principle



Availability of data and materials
All the original experimental data can be available from the citations, and the ncDENSE method can be available at https://github.com/ck-fighting/ncDENSE
References
Leontis NB, Westhof E. Geometric nomenclature and classification of RNA base pairs. RNA. 2001;7(4):499–512.
Mattick JS, Makunin IV. Non-coding RNA. Hum Mol Genet. 2006;15(Suppl–1):R17–29.
Wang X, Arai S, Song X, Reichart D, Du K, Pascual G, Tempst P, Rosenfeld MG, Glass CK, Kurokawa R. Induced ncRNAs allosterically modify RNA-binding proteins in cis to inhibit transcription. Nature. 2008;454(7200):126–30.
Moore MJ. From birth to death: the complex lives of eukaryotic mRNAs. Science. 2005;309(5740):1514–8.
Buccitelli C, Selbach M. mRNAs, proteins and the emerging principles of gene expression control. Nat Rev Genet. 2020;21(10):630–44.
Dinger ME, Pang KC, Mercer TR, Mattick JS. Differentiating protein-coding and noncoding RNA: challenges and ambiguities. PLoS Comput Biol. 2008;4(11): e1000176.
Wu PY, Phan JH, Wang MD: The effect of human genome annotation complexity on RNA-seq gene expression quantification. In: 2012 IEEE international conference on bioinformatics and biomedicine workshop. 2012.
Calin GA, Liu C-G, Ferracin M, Hyslop T, Spizzo R, Sevignani C, Fabbri M, Cimmino A, Lee EJ, Wojcik SE. Ultraconserved regions encoding ncRNAs are altered in human leukemias and carcinomas. Cancer cell. 2007;12(3):215–29.
Palazzo AF, Lee ES. Non-coding RNA: what is functional and what is junk? Front Genet. 2015;6:2.
Ebert MS, Sharp PA. MicroRNA sponges: progress and possibilities. Rna. 2010;16(11):2043–50.
Kung JTY, Colognori D, Lee JT. Long noncoding RNAs: past, present, and future. Genetics. 2013;193(3):651–69.
Lee JC, Gutell RR. Diversity of base-pair conformations and their occurrence in rRNA structure and RNA structural motifs. J Mol Biol. 2004;344(5):1225–49.
Grassi G, Dawson P, Guarnieri G, Kandolf R, Grassi M. Therapeutic potential of hammerhead ribozymes in the treatment of hyper-proliferative diseases. Curr Pharm Biotechnol. 2004;5(4):369–86.
Parenteau J, Durand M, Morin G, Gagnon J, Lucier JF, Wellinger RJ, Chabot B, Abou Elela S. Introns within ribosomal protein genes regulate the production and function of yeast ribosomes. Cell. 2011;147(2):320–31.
Brodel AK, Sonnabend A, Roberts LO, Stech M, Wustenhagen DA, Kubick S. IRES-mediated translation of membrane proteins and glycoproteins in eukaryotic cell-free systems. Plos One. 2013;8(12):e82234.
Henkin TM. Classic spotlight: regulatory function of leader RNAs. J Bacteriol. 2016;198(5):743–743.
Garst AD, Edwards AL, Batey RT. Riboswitches: structures and mechanisms. Csh Perspect Biol. 2011;3(6): a003533.
Huttenhofer A, Vogel J. Experimental approaches to identify non-coding RNAs. Nucleic Acids Res. 2006;34(2):635–46.
Childs L, Nikoloski Z, May P, Walther D. Identification and classification of ncRNA molecules using graph properties. Nucleic Acids Res. 2009;37(9):e66–e66.
Panwar B, Arora A, Raghava GPS. Prediction and classification of ncRNAs using structural information. Bmc Genomics. 2014;15:1–13.
Yu B, Lu Y, Zhang QC, Hou L. Prediction and differential analysis of RNA secondary structure. Quant Biol. 2020;8(2):109–18.
Wang LY, Zheng SG, Zhang H, Qiu ZY, Zhong XD, Liuliu HM, Liu YN. ncRFP: a novel end-to-end method for non-coding RNAs family prediction based on deep learning. IEEE/ACM Trans Comput Biol. 2021;18(2):784–9.
Wang LY, Zhong XD, Wang S, Liu YN. ncDLRES: a novel method for non-coding RNAs family prediction based on dynamic LSTM and ResNet. Bmc Bioinform. 2021;22(1):1–14.
Noviello TMR, Ceccarelli F, Ceccarelli M, Cerulo L. Deep learning predicts short non-coding RNA functions from only raw sequence data. PLoS Comput Biol. 2020;16(11): e1008415.
Winkle M, El-Daly SM, Fabbri M, Calin GA. Noncoding RNA therapeutics-Challenges and potential solutions. Nat Rev Drug Discov. 2021;20(8):629–51.
Chung J, Gulcehre C, Cho K, Bengio Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555 2014.
Wang Q, Xu C, Zhou Y, Ruan T, Gao D, He P: An attention-based Bi-GRU-CapsNet model for hypernymy detection between compound entities. In: 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). IEEE; 2018. p. 1031–1035.
He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. p. 770–778.
Huang G, Liu Z, Van Der Maaten L, Weinberger KQ. Densely connected convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. p. 4700–4708.
Zhang K, Guo Y, Wang X, Yuan J, Ding Q. Multiple feature reweight densenet for image classification. IEEE Access. 2019;7:9872–80.
Rodríguez P, Bautista MA, Gonzalez J, Escalera S. Beyond one-hot encoding: Lower dimensional target embedding. Image Vis Comput. 2018;75:21–31.
Acknowledgements
We thank all the editors and reviewers who worked on this article.
Funding
This work has been supported by the Natural Science Foundation of Jilin Province under Grant No.YDZJ202101ZYTS144, the National Key Research and Development Program Project, (National Science and Technology Development Fund) No. 151, 2020.
Author information
Authors and Affiliations
Contributions
CK designed the method, prepared the datasets, implemented the experiment, and wrote the manuscript; HL solved the work technical problems; WJH is responsible for preparing Figs. 1, 2, 3, 4, 5 and 6; LYN is responsible for guiding the idea of ncDENSE and revised the manuscript; ZXD guided the work ideas and revised the manuscript;LZ revised the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Chen, K., Zhu, X., Wang, J. et al. ncDENSE: a novel computational method based on a deep learning framework for non-coding RNAs family prediction. BMC Bioinformatics 24, 68 (2023). https://doi.org/10.1186/s12859-023-05191-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12859-023-05191-6