- Meeting abstract
- Open access
- Published:
A systematic study on latent semantic analysis model parameters for mining biomedical literature
BMC Bioinformatics volume 10, Article number: A6 (2009)
Background and rationale
Latent semantic analysis (LSA) is considered to be an efficient text mining technique [1] but most approaches developed on this paradigm are based on adhoc principles. A systematic study on the parameters affecting the performance of LSA is expected to provide guidelines to objectively select the LSA model parameters in a way that is consistent with the data and the application. In this study, empirical analyses were conducted using a previously published 50 gene data set [2] to examine the effects of the following parameters (outlined in Figure 1): Parameters are: (i) stemming, stop-words and word counts (to discard abstract with not enough information), (ii) corpus content (e.g., abstracts with and without titles), (iii) inclusion or exclusion of the dc component or 1st Eigen vector (that adds bias to the model), (iv) objective criteria to choose the number of factors (Eigen vectors) to create the model, (v) information theoretic criteria to select features (words in the corpus) instead of considering complete set of features.

Illustration of the methodology.
Methodology
Two datasets, one with titles and abstracts and the other with only abstracts were used to conduct empirical analyses. Preprocessing steps included stemming, stop word removal, as well as removal of documents with less than 100 terms. The term frequency-inverse document frequency (TF-IDF) matrix of size 8714*50 was constructed using the dataset. Singular value decomposition (SVD) on the TF-IDF matrix was used to compute the encoding of the dataset and only k components were retained based on the following objective criteria:
-
1.
Top 25 Eigen vectors
-
2.

,


: energy content within p Eigen vectors,

: Energy content with n (all) Eigen vectors
-
3.
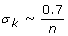
,
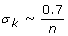
n: number of documents, k: indices of Eigen vector, S: singular value
In addition, the effect of bias was studied by excluding the 1st Eigen vector (dc component).
Different combinations of these parameters were studied and the performance of various LSA models was evaluated by determining the average precision, recall values. The best model is defined as the one with relatively high average precision across a set of varied queries.
Results and conclusion
Performance analysis (average precision-recall curves, F-measure etc.) using Gene Ontology classifications corresponding to the 50 gene collection show that not all parameters significantly affect the performance of LSA model (Table 1). In general, adding titles in addition to the abstracts substantially increased the average precision. In addition, using 0.7/n criteria produced better results than using 25 Eigen vectors or the 97% criteria. It was found that the best performance was achieved by combining 3 parameters: inclusion of title in abstracts in the corpus, exclusion of the dc component, and selection of Eigen vectors based on objective criterion (Figure 2). This work provides a framework for determining the best parameters in using LSA for ranking genes with respect to queries. Future work will focus on evaluating this framework using different gene document collections.

Average precision vs. rank curve. A combination of three parameters was used: inclusion of titles, exclusion of 1st Eigen vector and 0.7/n objective criterion for factor selection. This combination provides better performance than with individual parameters.
References
Vanteru BC, Shaik JS, Yeasin M: Semantically linking and browsing PubMed abstracts with gene ontology. BMC Genomics 2008, 9: S10. 10.1186/1471-2164-9-S1-S10
Homayouni R, Heinrich K, Wei L, Berry M: Gene clustering by latent semantic indexing of MEDLINE abstracts. Bioinformatics 2005, 21(1):104. 10.1093/bioinformatics/bth464
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is published under license to BioMed Central Ltd. This is an Open Access article is distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Yeasin, M., Malempati, H., Homayouni, R. et al. A systematic study on latent semantic analysis model parameters for mining biomedical literature. BMC Bioinformatics 10 (Suppl 7), A6 (2009). https://doi.org/10.1186/1471-2105-10-S7-A6
Published:
DOI: https://doi.org/10.1186/1471-2105-10-S7-A6