- Software
- Open access
- Published:
MultiLoc2: integrating phylogeny and Gene Ontology terms improves subcellular protein localization prediction
BMC Bioinformatics volume 10, Article number: 274 (2009)
Abstract
Background
Knowledge of subcellular localization of proteins is crucial to proteomics, drug target discovery and systems biology since localization and biological function are highly correlated. In recent years, numerous computational prediction methods have been developed. Nevertheless, there is still a need for prediction methods that show more robustness and higher accuracy.
Results
We extended our previous MultiLoc predictor by incorporating phylogenetic profiles and Gene Ontology terms. Two different datasets were used for training the system, resulting in two versions of this high-accuracy prediction method. One version is specialized for globular proteins and predicts up to five localizations, whereas a second version covers all eleven main eukaryotic subcellular localizations. In a benchmark study with five localizations, MultiLoc2 performs considerably better than other methods for animal and plant proteins and comparably for fungal proteins. Furthermore, MultiLoc2 performs clearly better when using a second dataset that extends the benchmark study to all eleven main eukaryotic subcellular localizations.
Conclusion
MultiLoc2 is an extensive high-performance subcellular protein localization prediction system. By incorporating phylogenetic profiles and Gene Ontology terms MultiLoc2 yields higher accuracies compared to its previous version. Moreover, it outperforms other prediction systems in two benchmarks studies. MultiLoc2 is available as user-friendly and free web-service, available at: http://www-bs.informatik.uni-tuebingen.de/Services/MultiLoc2.
Background
A eukaryotic cell is organized into different membrane-surrounded compartments which are specialized for different cellular functions. However, most cellular proteins are synthesized in the cytoplasm and need to be transported to their final location to fulfill their biological function. The whole protein sorting process is not completely understood but, in principle, it depends on signals in the amino acid sequence or signal patches on the protein surface.
There are diverse applications for the knowledge of the localization of the complete proteome, the localizome, in the fields of proteomics, drug target discovery and systems biology. Since subcellular localization is highly correlated with biological function, it is possible to draw conclusions from the knowledge of a protein's localization regarding its cellular role. Hence, subcellular localization is a key functional characteristic of proteins. Proteins destined for the extracellular space or the cell surface are especially of pharmaceutical interest as they are easily accessible drug targets. The integration of large-scale localization data with diverse omics data, produced by high-throughput techniques, will help in understanding cellular function. Localization data can be used to validate or analyze protein-protein interactions inferred from two-hybrid experiments or biochemical pathways inferred from microarray expression data.
In recent years large-scale sequencing projects have caused a rapid growth of sequence information and increased the number of proteins but without any further annotation in public databases. Determining the localization of proteins using experimental methods alone is expensive and time-consuming.
Fast and accurate computational prediction methods provide an attractive complement to experimental methods. In the last decade numerous computational methods, which can be roughly divided into sequence-based and annotation-based methods [1, 2], have been developed. Sequence-based predictors only use the amino acid sequence of the query protein as input. They are based either on the detection of sequence-coded sorting signals like N-terminal targeting peptides [3–11] and nuclear localization signals (NLS) [11] or use the fact that the amino acid composition of a protein is correlated with its localization [12]. The latter methods [2, 13–21] use different kinds of composition information like the overall, paired, gapped-paired, surface or pseudo amino acid composition from the protein sequence or sequence profiles. More recent and advanced methods combine composition information with the detection of sorting signals [22, 23]. Annotation-based predictors search the sequence for functional domains and motifs [24, 25] or use textual information like Swiss-Prot keywords [26, 27], Gene Ontology (GO) terms [28, 29] or PubMed abstracts [30, 31]. If such information is not available for the query protein most of these methods transfer annotation from close homologs. Nair and Rost [32] quantitatively showed that proteins with sufficiently similar sequences usually are close homologs that function at the same localization site. Annotation-based predictors often report higher performance than sequence-based predictors which, however, are more general and robust and can also be used for novel proteins for which no additional information is present and no annotated close homologs can be found. In addition to the predictors of the two categories, there are also hybrid approaches which combine sequence-based and annotation-based information [33–37] and can therefore profit from the advantages of both worlds. A further category are meta predictors, which integrate the prediction results of multiple tools [38, 39].
Although there already exist a lot of computational prediction methods, there is still room for improvement. This is due to the fact that the protein sorting process is very complex and not yet well understood. Only a small portion of proteins have clearly identifiable sorting signals in their primary sequence. As a consequence, available prediction methods are often either specialized for the prediction of very few localizations with higher accuracy or for the prediction of a wide range of localizations with reduced accuracy. A further challenge is how to deal with proteins present in multiple locations [40, 41].
The aim of this work was not to develop a completely novel algorithm or protein coding but to create a reliable and efficient predictor with maximum prediction accuracy. Especially, in the context of large-scale genome annotations scientific users rely on high-accuracy subcellular localization predictions. A difference of a few percent points in performance can mean hundreds of correctly or incorrectly classified proteins in genome annotation. Hence, well-tuned predictors can make a significant difference in this area. To this end, we extend our previously published support vector machine (SVM) based predictor MultiLoc [23], which utilizes overall amino acid composition and the presence of known sorting signals. We show that the performance of MultiLoc can be clearly improved by incorporating phylogenetic profiles and GO terms inferred from the primary sequence leading to a high-accuracy prediction system that covers all main eukaryotic subcellular localizations. Phylogenetic profiles encode evolutionary information in the form of patterns of protein inheritance among the species. Marcotte et al. [42] originally applied this approach to distinguish mitochondrial and non-mitochondrial proteins. GO terms were previously combined with sequence-based information in the form of pseudo amino acid composition in a group of predictors [36, 37].
The GO terms are used as primary prediction criteria and pseudo amino acid composition is used if no GO term can be found. Our extensive MultiLoc2 prediction system integrates composition and sorting signal information with phylogenetic profiles and GO terms towards a common localization prediction. The extended MultiLoc system is trained on two different datasets resulting in two versions with different resolutions. MultiLoc2-LowRes is a low resolution predictor that is specialized for globular proteins and predicts up to five localizations for animals, fungi and plants. MultiLoc2-HighRes is a high resolution predictor that covers all 11 main eukaryotic subcellular localizations. The main reason for creating MultiLoc2-LowRes additionally to MultiLoc2-HighRes is to provide a predictor with superior prediction accuracy for globular proteins. For certain applications it is sufficient to discriminate between secreted proteins and the localizations of globular proteins.
The MultiLoc2 approach was compared with current state-of-the-art tools (BaCelLo [19], LOCtree [2], Protein Prowler [9], TargetP [5] and WoLF PSORT [22]) using independent datasets sharing very low sequence identity with the training datasets of all compared tools. We found MultiLoc2 to perform considerably better than related tools for animals and plants and comparable for fungal proteins in a benchmark study with five localizations. Since GO terms are not always available, we evaluate MultiLoc2 as purely sequence-based and found the performance only slightly reduced but still better or comparable with other tools. Furthermore, MultiLoc2-HighRes performs clearly better compared with WoLF PSORT using a second independent dataset that extends the benchmark study to all main eukaryotic subcellular localizations. The second benchmark study was performed only between these two predictors since the remaining methods are specialized for a smaller amount of localizations. Both versions of MultiLoc2 are available online as web interface at http://www-bs.informatik.uni-tuebingen.de/Services/MultiLoc2. The online version provides fast access to MultiLoc2 for a limited number of query sequences. Furthermore, a stand-alone version (including the source code of the method) is available from the website. The stand-alone version is suitable for large-scale offline prediction jobs.
In the following sections the MultiLoc2 system is described in detail together with the training and test datasets used, followed by the performance evaluation and the results of the benchmark studies.
Implementation
MultiLoc2 architecture
The MultiLoc prediction system described earlier [23] is based on the integration of the output of four sequence-based subclassifiers (SVMTarget, SVMSA, SVMaac and MotifSearch) into a protein profile vector. The subclassifiers utilize the overall amino acid composition or search for specific sorting signals. MultiLoc2 extends the original architecture with two new classifiers based on phylogenetic profiles (PhyloLoc) and GO terms (GOLoc). As stated in the introduction, there are two versions of MultiLoc2 which differ in the number of predictable localizations. MultiLoc2-HighRes can deal with nuclear (nu), cytoplasmic (cy), mitochondrial (mi), chloroplast (ch), extracellular (ex), plasma membrane (pm), peroxisomal (pe), endoplasmic reticulum (er), Golgi apparatus (go), lysosomal (ly) and vacuolar (va) proteins. MultiLoc2-LowRes is specialized for globular proteins and predicts secretory pathway (SP) proteins (separated into the six classes ex, pm, er, go, ly, va in MultiLoc2-HighRes) as well as nu, cy, mi and ch. Similar to its previous version, MultiLoc2 is available for plant, animal and fungal protein localization prediction. A scheme of the overall architecture of MultiLoc2 is shown in Fig. 1. A query sequence is processed by a first layer of six subprediction methods. The results from these methods are collected in the protein profile vector, which is used as input for the final layer of SVMs, which in turn outputs the final localization prediction. In both layers one-vs-one SVMs are used for classification. The corresponding figure of MultiLoc2-LowRes is also available [see Additional file 1]. The original four sequence-based classifiers are briefly described in the next section, followed by details of PhyloLoc and GOLoc.

MultiLoc2 architecture. The architecture of MultiLoc2-HighRes (animal version). A query sequence is processed by a first layer of six subprediction methods (SVMTarget, SVMSA, SVMaac, PhyloLoc, GOLoc and MotifSearch). The two new subprediction methods, PhyloLoc and GOLoc, are highlighted in bold. The individual output of the methods of the first layer are collected in the protein profile vector (PPV), which enters a second layer of SVMs producing probability estimates for each localization.
Subprediction methods
SVMTarget
SVMTarget is based on the detection of N-terminal targeting peptides to predict ch, mi, SP and other (OT) localizations for plant proteins and only mi, SP and OT for animal and fungal proteins. A sliding window approach scans the N-terminal part of a given query sequence. The partial amino acid composition in the window is used as input for the SVMs. The output of SVMTarget is a probability for each localization.
SVMSA
SVMSA scans the sequence for a signal anchor (SA) which can be present in membrane proteins of the secretory pathway instead of a signal peptide. Therefore, SVMSA complements SVMTarget. SAs are also detected using a sliding window approach based on partial amino acid composition. SVMSA is specialized for membrane proteins and is therefore not included in MultiLoc2-LowRes.
SVMaac
SVMaac is based on the overall amino acid composition of the query sequence and outputs a probability for each localization. In contrast to the original MultiLoc, the binary one-versus-all classification is replaced by a one-versus-one procedure since a slightly performance increase could be achieved.
MotifSearch
MotifSearch outputs five binary features that encode the presence or absence of sequence motifs relevant to protein sorting such as nuclear localization signals (NLSs). Two additional binary features represent the presence or absence of a DNA-binding domain or a plasma membrane receptor domain.
PhyloLoc
Proteins within the same subcellular localization tend to share a similar taxonomic distribution of homologous proteins in other genomes [42]. This kind of information can be represented as a profile [43] which encodes the pattern of presence or absence of a given protein in a set of genomes. Marcotte et al. [42] applied phylogenetic profiles for the distinction of mitochondrial and non-mitochondrial proteins using 31 genomes and a linear discrimination function. PhyloLoc is based on phylogenetic profiles derived from 78 fully sequenced genomes and SVMs to predict all of the localizations of the MultiLoc2 predictors. The genomes were retrieved from the National Center for Biotechnology Information (NCBI) web site (downloaded between 6th and 9th February 2008). We used all available eukaryotic (20) and archaean (33) genomes and a non-redundant set of 25 bacterial genomes [see Additional file 1]. The input of PhyloLoc (as shown in Fig. 2) is a vector of similarities between the query sequence and the best sequence match in each genome using BLAST. The BLAST homology searches are performed using default settings. The bit score B qi of the best sequence match of the query sequence q in genome i and the self bit score B qq of q aligned with itself are used to calculate the similarity S qi which is defined as: S qi = B qi /B qq . Due to the fact that B qi is always smaller than B qq , the values of S qi range from zero to one. Values close to one indicate presence of the query protein and values close to zero indicate absence. The calculation of phylogenetic profiles based on bit scores was also previously used for the functional annotation of bacterial genomes [44]. An important point to note is that, although BLAST is used, creating phylogenetic profiles is not an annotation-based or homology-based method as sometimes described in the literature. The reason is that there is no annotation-transfer from the aligned sequences. Actually, it is irrelevant whether the proteins of the genomes are annotated or not. Proteins with similar phylogenetic profiles are co-inherited and do not have to be close homologs [45].

PhyloLoc and GOLoc architecture. The architectures of PhyloLoc and GOLoc from MultiLoc2-LowRes. The input of PhyloLoc is a vector of similarities (phylogenetic profile) between the query sequence and the best sequence match in each genome inferred from BLAST. The input of GOLoc is a binary-coded vector representing the GO terms of the query sequence inferred from InterPro using InterProScan. PhyloLoc and GOLoc use one-versus-one SVMs to process their input and to calculate probability estimates for each localization.
GOLoc
The Gene Ontology (GO) is a controlled vocabulary for uniformly describing gene products in terms of biological processes, cellular components and molecular function across all organisms [46]. It has been shown that GO terms can be used to improve the performance of subcellular protein localization prediction methods [47, 48]. In the literature to date, there are three possibilities for obtaining GO annotation terms for a query sequence. If the UniProt [49] accession number is known, one can simply extract the GO annotation from the UniProt database [50]. However, this procedure fails for novel proteins without accession number. Another possibility is to search for homologous proteins annotated with GO terms using BLAST [28, 29]. This becomes difficult in cases where proteins have no close homolog or proteins have many homologs, because no GO term can be obtained or GO terms might be ambiguous. A further method of inferring GO terms is InterProScan [51] used, for example, by Chou and Cai [52]. Given a protein sequence, the tool scans against various pattern and signature data sources collected by the InterPro project [53]. InterPro also provides a mapping of the detected protein domains and functional sites to GO terms.
Our subpredictor GOLoc is based on GO terms calculated using InterProScan. Since the GO terms are derived directly from the query sequence, we avoid the drawbacks of using accession numbers or BLAST. The input of GOLoc is a binary-coded vector which represents all GO terms of the training sequences (see Fig. 2). GO terms present in the query sequence are set to 1 in the vector and to 0 otherwise [see Additional file 1].
Datasets
BaCelLo
The datasets used for training and testing MultiLoc2-LowRes against comparable predictors were obtained from the BaCelLo website. The homology-reduced training dataset was extracted from Swiss-Prot release 48 and contains 2597 animal, 1198 fungal and 491 plant proteins resulting in three kingdom-specific predictors. By ignoring proteins annotated as 'membrane' or 'transmembrane', only globular proteins were considered.
The animal and fungal proteins represent four localizations (nu, cy, mi, SP) and the plant proteins five localizations (with the addition of ch). The independent test dataset (BaCelLo IDS) was extracted from Swiss-Prot release 54. Only proteins added to the database starting from release 49 were considered. Furthermore, proteins sharing a sequence identity >30% to at least one protein from release 48 were removed. This ensured that all test proteins were novel to the predictors in the benchmark study since all of them were trained using Swiss-Prot proteins up to release 48. In order to avoid a bias towards the prediction of over-represented protein classes, all sequences which share the same localization and a sequence identity >30% were clustered into 432 animal, 418 fungi and 132 plant groups. More information concerning the creation of the BaCelLo data sets can be found in Pierleoni et al [19] and Casadio et al. [54].
Höglund
For training MultiLoc2-HighRes we applied the original dataset used to train MultiLoc [23], which contains 5959 eukaryotic proteins extracted from Swiss-Prot release 42. The data set covers 11 localizations (cy, ch, er, ex, go, ly, mi, nu, pe, pm, va). To also compare the prediction performance of MultiLoc2 with WoLF PSORT in regard to the localizations not present in the BaCelLo test dataset, we created a second independent dataset (Höoglund IDS) which covers seven localizations (er, ex, go, ly, pe, pm, va). Therefore, animal, fungal and plant proteins of these localizations were extracted from Swiss-Prot release 55.3 in the same way as the BaCelLo independent dataset. However, in the case of the plant proteins, we increased the allowed sequence identity threshold to 40% in order to obtain enough data. We used BLASTClust to cluster the sequences using 30% pairwise sequence identity for the animal and fungal proteins and 40% for the plant proteins. The whole procedure delivered 158 animal, 106 fungi and 30 plant groups.
For each training dataset (BacelLo and Höglund), a table that shows the number of protein sequences for each localization is listed elsewhere [see Additional file 1]. Two different datasets were used for training since this allows a more objective performance comparison between MultLoc2-HighRes and its predecessor MultiLoc on the one hand and in particular between MultLoc2-LowRes and further methods on the other hand.
SVM training and performance evaluation
All building blocks (except MotifSearch) of MultiLoc2 were trained using SVMs [55] from the LIBSVM [56] software. Throughout, we used the radial basis kernel function and optimized the c and g parameters by grid search. Furthermore, we defined weights for each class in order to reduce the over-prediction effect when using unbalanced training datasets. To this end, we used built-in functionality of LIBSVM. The weighting scheme assigns weight 1.0 to the largest class and higher weights to the remaining classes. The weights of these classes are simply calculated by dividing the size of the largest class by that of each smaller class. The probability estimates calculated by LIBSVM were used for ranking the final predicted localizations and choosing the most probable one.
We used five-fold cross-validation for training and evaluating the prediction performance. Additionally, independent datasets were used for testing MultiLoc2 and comparison with other prediction methods. Therefore, all test proteins share low sequence similarity with proteins in the training datasets.
Localization-specific performance results were expressed using sensitivity (SE), specificity (SP) and the Matthews correlation coefficient (MCC) defined as:
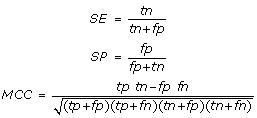
To evaluate the overall prediction performance, we used average sensitivity (AVG), which is also known as the average localization-specific accuracy, as primary measure. The average sensitivity is better suited than the overall accuracy (ACC), the percentage of correctly predicted proteins of all localizations. The reason is that all prediction methods are trained on unbalanced datasets with strongly varying numbers of proteins per localization. This often biases the prediction towards the localization with the most representations in the training dataset. Hence an unbalanced test dataset would also normally lead to a distorted performance evaluation when using the ACC only. To calculate the performance measures for the independent datasets, we used the average rates of true and false predicted proteins within each cluster.
Results and discussion
Cross-validation performance
The impact of the MultiLoc2 extensions on the overall prediction performance was evaluated using 5-fold cross-validation. The results are summarized in Table 1. The average sensitivity and overall accuracy of MultiLoc2-LowRes (trained on the BaCelLo dataset) and MultiLoc2-HighRes (trained on the Höglund dataset) are compared with those of the original MultiLoc architecture and MultiLoc extended by PhyloLoc as well as GOLoc only. Using the BaCelLo dataset, MultiLoc2-LowRes yields a clearly higher AVG (85.0% for animals, 83.9% for fungi and 81.6% for plants) than the original MultiLoc (77.3%, 78.4% and 71.4% respectively). For the Höglund dataset the AVG is increased from 78.6% to 89.2% for animal, from 78.0% to 89.2% for fungal and from 78.0% to 89.4% for plant proteins by the MultiLoc2-HighRes system compared to the original MultiLoc. Note that the performance results for the original MultiLoc differ from those previously reported [23] since the SVMaac architecture has slightly changed. Adding PhyloLoc or GOLoc individually to MultiLoc already increased the performance considerably, whereas the performance gain caused by GOLoc is slightly higher compared to PhyloLoc. However, the best performance is achieved by the addition of both subpredictors, obtaining MultiLoc2. Similar trends can be detected regarding the overall accuracies. The standard deviations of the MultiLoc2-LowRes plant version are higher compared to the other versions due to the fact that the number of training sequences in the dataset is considerably lower.
Comparison with related tools
In a recently published study [54] five selected top-performing sequence-based prediction methods (BaCelLo, LOCtree, Protein Prowler, TargetP and WoLF PSORT) were compared using an independent dataset (see Section 2.3.1). Based on this benchmark study, we compared the performance of MultiLoc2 against these five methods using the same test setting. The benchmark study considered five subcellular localizations (nu, cy, mi, ch, SP). Furthermore, a virtual class nu/cy, containing nu and cy proteins, was created in order to ensure a fair comparison with TargetP and Protein Prowler which do not discriminate between these two localizations. To deal with WoLF PSORT and LOCtree, predicted sublocalizations of the secretory pathway were grouped into the SP class. A similar approach was followed for the evaluation of MultiLoc2-HighRes. Depending on the inclusion of the virtual nu/cy class, the number of tested classes is three or four for animals and fungi as well as four or five for plants. We also evaluated the performance of only sequenced-based predictions of MultiLoc2 by disregarding GO terms to simulate the case of unavailability of GO terms. Table 2 shows the localization-specific performance results using sensitivity, specificity and MCC and Table 3 summarizes the overall performances using AVG and ACC. Note that the number of SP clusters for fungi (9) and plants (6) and the mi clusters for plants (6) is quite small compared to the remaining localizations. Therefore, some care should be taken when interpreting the prediction results. Small clusters have only a small influence on the ACC, however, a large influence on the AVG.
MultiLoc2-LowRes always yields the highest ACCs and AVGs for animal and plant proteins and hence outperforms all other predictors. The reason for this outstanding result is that MultiLoc2-LowRes is, in general, better suited to discriminate between nu and cy and between mi and ch proteins (see Table 2), which is a known challenge in the prediction of protein subcellular localization. For fungal proteins the ACCs are the highest and the AVGs are the second highest after the BaCelLo predictor. One reason for the reduced AVG performance is that on average only 34% of the fungal proteins are annotated with GO terms by InterProScan. The annotation-rate is higher for animals (43%) and plants (79%). Compared to MultiLoc2-LowRes, the performance of MultiLoc2-HighRes is, not surprisingly, reduced, since it is a more general predictor not specialized for globular proteins and covering a wider range of localizations. However, for animal and plant proteins the AVGs of MultiLoc2-HighRes are equal or higher compared to the remaining methods. Similar to MultiLoc2-LowRes, MultiLoc2-HighRes performs worse for fungal proteins. The AVGs are still better than LOCtree, however, worse compared with Protein Prowler, TargetP and WoLF PSORT.
If we simulate the case in which no GO terms are available for any test proteins, the overall performances of the MultiLoc2 predictors are slightly reduced but still better than those of the other methods for animal and plant and comparable for fungal proteins [see Additional file 1].
In a second benchmark study, MultiLoc2-HighRes and WoLF PSORT were compared using the Höglund independent dataset (see Section 2.3.2). In contrast to the other predictors, both methods allow the prediction of all main eukaryotic subcellular localizations. We further note that WoLF PSORT can also distinguish between the cytoskeleton within the cytoplasm. In this comparison we only consider those localizations (ex, pm, pe, er, go, ly, va) not tested in the previous study. Since it is known that discriminating between these classes is challenging, we also evaluated whether the tested proteins could be correctly predicted within the top three ranked localizations. The results of this study are summarized in Table 4. MultiLoc2-HighRes always achieves clearly higher AVGs. In particular, the AVG within the top three locations of MultiLoc2 is about twice as high as that of WoLF PSORT. A similar result is observed regarding the ACCs. MultiLoc2-HighRes has a much lower bias towards overrepresented localizations and, thus, almost never shows zero sensitivity for a localization with few representatives. This again proves high robustness of MultiLoc2, even in cases of many localizations.
Conclusion
Our new approach for predicting protein subcellular localization, MultiLoc2, integrates several subpredictors based on the overall amino acid composition, the detection of sorting signals, phylogenetic profiles and GO terms. Compared to the original MultiLoc architecture, the robustness and prediction performance is clearly improved. The different resolutions of MultiLoc2 were compared with current state-of-the-art sequence-based methods using independent datasets.
MultiLoc2-LowRes is specialized for globular proteins and offers kingdom-specific prediction of up to five localizations based on the BaCelLo dataset. On the other hand, MultiLoc2-HighRes is able to deal with membrane proteins and predicts all of the main eukaryotic localizations based on a dataset that consists of a mixture of animal, fungal and plant proteins. In comparison with five other methods, the MultiLoc2 predictors performed better for animal and plant proteins whereas MultiLoc2-LowRes outperforms MultiLoc2-HighRes in general. However, the performance of MultiLoc2-HighRes is remarkable since it is able to predict more localizations than the other tools except for WoLF PSORT. We also simulated the scenario in which no GO term is available for any test proteins, which makes the prediction sequence-based only. The resulting performance of the MultiLoc2 predictors is slightly reduced but still better for animals and plants and comparable for fungi. Therefore, we conclude that the MultiLoc2 approach is very robust and well suited for novel proteins without relevant sequence similarity to annotated proteins but can also benefit from the presence of calculated GO annotation from the sequence using InterProScan.
In a second benchmark study we evaluated the prediction performance of MultiLoc2-HighRes compared to WoLF PSORT for proteins localized in the peroxisomes and in the sublocalizations of the secretory pathway. For all three eukaryotic kingdoms, MultiLoc2-HighRes performs clearly better. In particular, MultiLoc2-HighRes shows much better sensitivity throughout all localizations and yields high robustness. However, the results indicate that the classification in all main eukaryotic localizations is still a challenging task and leaves room for improvement for future work.
The flexible architecture of MultiLoc2 is based on the easily extendable protein profile vector. In the future, this will allow us to integrate more heterogeneous and relevant information to further improve the prediction accuracy. In particular, we plan to investigate in further sequences-based or annotation-based information such as protein-protein interaction and text-terms from PubMed abstracts. Moreover, handling of proteins present in multiple locations is an open challenge.
Availability and requirements
-
Project name: MultiLoc2
-
Project home page: http://www-bs.informatik.uni-tuebingen.de/Services/MultiLoc2
-
Operating system(s): Linux
-
Programming language: Python
-
Other requirements: LIBSVM 2.8 or higher, BLAST 2.2.14 or higher, InterProScan 4.3 or higher (optional)
-
License: GNU GPL
-
Any restrictions to use by non-academics: None
References
Emanuelsson O, Brunak S, von Heijne G, Nielson H: Locating proteins in the cell using TargetP, SignalP and related tools. Nat Protoc 2007, 2(4):953–71. 10.1038/nprot.2007.131
Nair R, Rost B: Mimicking Cellular Sorting Improves Prediction of Subcellular Localization. J Mol Biol 2005, 348: 85–100. 10.1016/j.jmb.2005.02.025
Emanuelsson O, Nielson H, von Heijne G: ChloroP, a neural network-based method for predicting chloroplast transit peptides and their cleavage sites. Protein Sci 1999, 8: 978–984. 10.1110/ps.8.5.978
Bendtsen JD, Nielsen H, von Heijne G, Brunak S: Improved prediction of signal peptides: SignalP 3.0. J Mol Biol 2004, 340: 783–795. 10.1016/j.jmb.2004.05.028
Emanuelsson O, Nielson H, Brunak S, von Heijne G: Predicting subcellular localization of proteins based on their N-terminal amino acid sequence. J Mol Biol 2000, 300: 1005–1016. 10.1006/jmbi.2000.3903
Bannai H, Tamada Y, Maruyama O, Nakai K, Miyano S: Extensive feature detection of N-terminal protein sorting signals. Bioinformatics 2002, 18: 298–305. 10.1093/bioinformatics/18.2.298
Petsalaki EI, Bagos PG, Litou ZI, Hamodrakas SJ: PredSL: a tool for the N-terminal sequence-based prediction of protein subcellular localization. Genomics Proteomics Bioinformatics 2006, 4: 48–55. 10.1016/S1672-0229(06)60016-8
Fujiwara Y, Asogawa M: Prediction of subcellular localizations using amino acid composition and order. Genome Inform 2001, 12: 103–112.
Boden M, Hawkins J: Prediction of subcellular localization using sequence-biased recurrent networks. Bioinformatics 2005, 21: 2279–2286. 10.1093/bioinformatics/bti372
Small I, Peeters N, Legeai F, Lurin C: Predotar: A tool for rapidly screening proteomes for N-terminal targeting sequences. Proteomics 2004, 4: 1581–1590. 10.1002/pmic.200300776
Cokol M, Nair R, Rost B: Finding nuclear localization signals. EMBO Rep 2000, 1: 411–415. 10.1093/embo-reports/kvd092
Andrade MA, O'Donoghue SI, Rost B: Adaptation of protein surfaces to subcellular location. J Mol Biol 1998, 276: 517–525. 10.1006/jmbi.1997.1498
Cedano J, Aloy P, Pérez-Pons JA, Querol E: Relation between amino acid composition and cellular location of proteins. J Mol Biol 1997, 266: 594–600. 10.1006/jmbi.1996.0804
Reinhardt A, Hubbard T: Using neural networks for prediction of the subcellular location of proteins. Nucleic Acids Res 1998, 26: 2230–2236. 10.1093/nar/26.9.2230
Hua S, Sun Z: Support vector machine approach for protein subcellular localization prediction. Bioinformatics 2001, 17: 721–728. 10.1093/bioinformatics/17.8.721
Park KJ, Kanehisa M: Prediction of protein subcellular locations by support vector machines using compositions of amino acids and amino acid pairs. Bioinformatics 2003, 19: 1656–1663. 10.1093/bioinformatics/btg222
Xie D, Li A, Wang M, Fan Z, Feng H: LOCSVMPSI: a web server for subcellular localization of eukaryotic proteins using SVM and profile of PSI-BLAST. Nucleic Acids Res 2005, 33: W105-W110. 10.1093/nar/gki359
Guo J, Lin Y: TSSub: eukaryotic protein subcellular localization by extracting features from profiles. Bioinformatics 2006, 22: 1784–1785. 10.1093/bioinformatics/btl180
Pierleoni A, Martelli PL, Fariselli PL, Casadio R: BaCelLo: a balanced subcellular localization predictor. Bioinformatics 2006, 22(14):e408–16. 10.1093/bioinformatics/btl222
Cui Q, Jiang T, Liu B, Ma S: Esub8: a novel tool to predict protein subcellular localizations in eukaryotic organisms. BMC Bioinformatics 2004, 5: 66. 10.1186/1471-2105-5-66
Chou K, Cai Y: Prediction and classification of protein subcellular location - Sequence-order effect and pseudo amino acid composition. J Cell Biochem 2003, 90: 1250–1260. 10.1002/jcb.10719
Horton P, Park KJ, Obayashi T, Fujita N, Harada H, Adams-Collier CJ, Nakai K: WoLF PSORT: protein localization predictor. Nucleic Acids Res 2007, 35: W585–587. 10.1093/nar/gkm259
Höglund A, Dönnes P, Blum T, Adolph HW, Kohlbacher O: MultiLoc: prediction of protein subcellular localization using N-terminal targeting sequences, sequence motifs and amino acid composition. Bioinformatics 2006, 22: 1158–1165. 10.1093/bioinformatics/btl002
Chou K, Cai Y: Using functional domain composition and support vector machines for prediction of protein subcellular location. J Biol Chem 2002, 277: 45765–45769. 10.1074/jbc.M204161200
Scott MS, Thomas DY, Hallett MT: Predicting subcellular localization via protein motif co-occurrence. Genome Res 2004, 14: 1957–1966. 10.1101/gr.2650004
Nair R, Rost B: Inferring sub-cellular localization through automated lexical analysis. Bioinformatics 2002, 18: S78-S86.
Lu Z, Szafron D, Greiner R, Lu P, Wishart DS, Poulin B, Anvik J, Macdonell C, Eisner R: Predicting subcellular localizations of proteins using machine-learned classifiers. Bioinformatics 2004, 20: 547–556. 10.1093/bioinformatics/btg447
Lei Z, Dai Y: Assessing protein similarity with Gene Ontology and its use in subnuclear localization prediction. BMC Bioinformatics 2006, 7: 491. 10.1186/1471-2105-7-491
Huanq WL, Tunq CW, Ho SW, Hwang SF, Ho SY: ProLoc-GO: utilizing informative Gene Ontology terms for sequence-based prediction of protein subcellular localization. BMC Bioinformatics 2008, 9: 80. 10.1186/1471-2105-9-80
Brady S, Shatkay H: EpiLoc: a (working) text-based system for predicting protein subcellular location. In Pac Symp Biocomput Edited by: Altman RB. 2008, 604–15.
Fyshe A, Liu Y, Szafron D, Greiner R, Lu P: Improving subcellular localization prediction using text classification and the gene ontology. Bioinformatics 2008, 24: 2512–2517. 10.1093/bioinformatics/btn463
Nair R, Rost B: Sequence conserved for subcellular localization. Protein Sci 2002, 11: 2836–2847. 10.1110/ps.0207402
Shatkay H, Höglund A, Brady S, Blum T, Dönnes P, Kohlbacher O: SherLoc: high-accuracy prediction of protein subcellular localization by integrating text and protein sequence data. Bioinformatics 2007, 23: 1410–1417. 10.1093/bioinformatics/btm115
Guda C, Subramaniam S: pTARGET: A new method for predicting protein subcellular localization in eukaryotes. Bioinformatics 2005, 21: 3963–3969. 10.1093/bioinformatics/bti650
Bhasin M, Raghava GP: ESLpred: SVM-based method for subcellular localization of eukaryotic proteins using dipeptide composition and PSI-BLAST. Nucleic Acids Res 2004, 32: W414-W419. 10.1093/nar/gkh350
Chou K, Shen H: Recent progress in protein subcellularlocation prediction. Anal Biochem 2007, 370: 1–16. 10.1016/j.ab.2007.07.006
Chou K, Shen H: Cell-PLoc: a package of Web servers for predicting subcellular localization of proteins in various organisms. Nat Protoc 2008, 3: 153–162. 10.1038/nprot.2007.494
Shen YO, Burger G: 'Unite and conquer': enhanced prediction of protein subcellular localization by integrating multiple specialized tools. BMC Bioinformatics 2007, 8: 420. 10.1186/1471-2105-8-420
Liu J, Kang S, Tang G, Ellis LBM, Li T: Meta-prediction of protein subcellular localization with reduced voting. Nucleic Acids Res 2007, 35: e96. 10.1093/nar/gkm562
Chou K, Shen H: Euk-mPLoc: a fusion classifier for large-scale eukaryotic protein subcellular location prediction by incorporating multiple sites. J Proteome Res 2007, 6: 1728–1734. 10.1021/pr060635i
Shen H, Chou K: Hum-mPLoc: an ensemble classifier for large-scale human protein subcellular location prediction by incorporating samples with multiple sites. Biochem Biophys Res Commun 2007, 355: 1006–1011. 10.1016/j.bbrc.2007.02.071
Marcotte EM, Xenarios I, Bliek AM, Eisenberg D: Localizing proteins in the cell from their phylogenetic profiles. Proc Natl Acad Sci USA 2000, 97: 12115–12120. 10.1073/pnas.220399497
Pellegrini M, Marcotte EM, Thompson MJ, Eisenberg D, Yeates TO: Assigning protein functions by comparative genome analysis. Proc Natl Acad Sci USA 1999, 96: 4285–4288. 10.1073/pnas.96.8.4285
Enault K, Suhre C, Poirot O, Clavarie JM: Finding nuclear localization signals. Bioinformatics 2003, 19: i105-i107. 10.1093/bioinformatics/btg1013
Marcotte EM: Computational genetics: finding protein function by nonhomology methods. Curr Opin Struct Biol 2000, 10: 359–365. 10.1016/S0959-440X(00)00097-X
Ashburner , et al.: Gene ontology: tool for the unification of biology. The Gene Ontology Consortium. Nat Genet 2000, 25: 25–29. 10.1038/75556
Chou K, Cai Y: A new hybrid approach to predict subcellular localization of proteins by incorporating Gene Ontology. Biochem Biophys Res Commun 2003, 311: 743–747. 10.1016/j.bbrc.2003.10.062
Lu Z, Hunter L: GO molecular function terms are predictive of subcellular localization. In Pac Symp Biocomput Edited by: Altman RB. 2005, 151–61.
Bairoch , et al.: The Universal Protein Resource(UniProt). Nucleic Acids Res 2005, 33: D154-D159. 10.1093/nar/gki070
Shen HB, Yanq J, Chou KC: Euk-PLoc: an ensemble classifier for large-scale eukaryotic protein subcellular location prediction. Amino Acids 2007, 33: 57–67. 10.1007/s00726-006-0478-8
Zdobnov EM, Apweiler R: InterProScan - an integration platform for the signature-recognition methods in InterPro. Bioinformatics 2001, 17: 847–848. 10.1093/bioinformatics/17.9.847
Chou K, Cai Y: Prediction of protein subcellular locations by GO-FunD-PseAA predictor. Biochem Biophys Res Commun 2004, 320: 1236–1239. 10.1016/j.bbrc.2004.06.073
Mulder NJ, et al.: New developments in the InterPro database. Nucleic Acids Res 2007, 35(Database issue):D224–8. 10.1093/nar/gkl841
Casadio R, Martelli PL, Pierleoni A: The prediction of protein subcellular localization from sequence: a shortcut to functional genome annotation. Brief Funct Genomic Proteomic 2008, 7: 63–73. 10.1093/bfgp/eln003
Vapnik VN: The Nature of Statistical Learning Theory. New York, USA: Springer-Verlag New York, Inc; 1999.
Chang CC, Lin CJ:LIBSVM: a library for support vector machines. 2001. [http://www.csie.ntu.edu.tw/~cjlin/libsvm]
Acknowledgements
S.B. gratefully acknowledges financial support from LGFG Promotionsverbund "Pflanzliche Sensorhistidinkinasen".
Author information
Authors and Affiliations
Corresponding author
Additional information
Authors' contributions
All the authors have read and approved the final manuscript.
Electronic supplementary material
12859_2009_3004_MOESM1_ESM.pdf
Additional file 1: Supplementary Materials. Supplementary Materials (PDF file) include description of some methodology details such as the NCBI genomes used in PhyloLoc, the number of GO terms used in GOLoc, and an overview of the MultiLoc2-LowRes architecture. In addition, result details are provided including the performance evaluation on the independent datasets without GO terms. (PDF 353 KB)
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
{kind=link}
{kind=link}
Rights and permissions
This article is published under license to BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Blum, T., Briesemeister, S. & Kohlbacher, O. MultiLoc2: integrating phylogeny and Gene Ontology terms improves subcellular protein localization prediction. BMC Bioinformatics 10, 274 (2009). https://doi.org/10.1186/1471-2105-10-274
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2105-10-274